IoPLMaterials
(F)AQ
OCaml に関する質問
eval $(opam env)
ターミナルに毎回
eval $(opam env)を打ち込むのが面倒です(そうしないとutopが起動しない)。
こちらのdirenvに関する部分を参照。
OCamlにおいて繰り返し構文の中身が unit 型なのはなぜ
OCamlにおいて繰り返し構文の中身が unit 型に限定されているなど、機能が限定されているのは何故でしょうか。
正しい答えと言えるかどうか自信がないですが,繰り返し構文の本体部分を unit 型に制限することで,評価結果に意味のある繰り返しを伴う計算は再帰関数で,評価結果に意味はなく繰り返すこと自体に意味がある(つまり副作用を使って計算する)ような繰り返し計算はforやwhileなどの繰り返し構文で書かせることを推奨できるというのはあるかもしれません.例えば1からnまでの整数の和を計算するプログラムの書き方として
let rec sum n = if n = 0 then 0 else n + (sum (n-1))
という書き方と
let sum n =
let i = ref n in
let s = ref 0 in
while !i > 0 do
s := !s + !i;
i := !i - 1
done;
!s
という2つの書き方がありますが,1からnまでの和という計算結果に意味があるこのような計算では後者より前者の方がスッキリしています.
他方,”Hello!”とn回画面に表示するようなプログラムは
let hello n =
if n = 0 then ()
else Printf.printf "Hello!\n"; hello (n-1)
という書き方と
let hello n =
for i = 0 to n - 1 do
Printf.printf "Hello!\n"
done
がありますが,こういう画面に何かを表示するという副作用を伴うプログラムでは後者もまあまあスッキリしていますね.(僕はこういう場合も前者で結構書いちゃう気もする...)
ループにするか再帰にするか
調べてみたところ、OCamlだけでなく関数型言語一般において、あまりfor文を使わないということは分かったのですが、その理由はどのようなものでしょうか。
おそらく再帰関数を使う方が for 文や while 文よりもより柔軟な繰り返しのパターンが書けるからかなあと思います.例えばアッカーマン関数という
let rec ack m n =
if m = 0 then
n+1
else if n = 0 then
ack (m-1) 1
else
ack (m-1) (ack m (n-1));;
で定義される関数があるのですが,これを while や for で表現するの大変そう.(ところで,これのmを大きくしたときの振る舞いと,nを大きくしたときの振る舞いをそれぞれチェックしてみるといいですよ.)また,マッカーシーの91関数という
let rec mc91 n =
if n > 100 then
n - 10
else
mc91 (mc91 (n+11));;
こういう関数があるのですが,これも for や while で書くの大変そうですね.(さあこの関数に101以下の整数を与えてみましょう.)
仮引数の ()
仮引数として与える
()は省略できますか?
OCaml では(Scala 等のように)() を省略することはできません.
なお,質問からするとオフトピックですが,OCaml にはラベル付き引数があり,これを使って省略可能な引数を持つ関数を実装することができます.
OCamlのリソース
たくさんあるのと僕も少ししかないのでなかなか紹介しきれませんが,例えばopam の全パッケージを人気順に並べたページを眺めてみたり,GitHub の OCaml で書かれたリポジトリのトレンドを眺めてみると面白いものが見つかったりするかもしれません.また,OCaml のメーリングリストやフォーラムも情報収集に良いと思います.OCamlの日本語Slackもあります.また,StackOverflowのocamlの質問集もそのような情報が流れていそうな気がします.OCaml のフォーラムでも活発に議論が行われているようです.
コンストラクタと関数適用
(S (S (S Z)))やf @@ xが正しく評価される一方でS @@ S @@ S @@ ZやS @@ Zはエラーを起こしました。ここから、コンストラクタは通常の関数とはやや異なるものとして実装されているらしいことがわかりますが、直感的には、ZやSはnatやnat -> nat型の値や関数と同一視できそうな気がします。これが通常の関数と異なる挙動をするのはどのような都合や目的によるものなのでしょうか。
はい,実際に SML や SML# というML言語の一種ではコンストラクタが関数として使えますし,Haskellも使えます.OCamlでそうなっている理由はちょっと分からないです.もしコンストラクタSを関数として使いたい場合はSの代わりにfun x -> S xを使うのが良いように思います.後者は値 x を受け取って S x を返す関数で,S を関数として扱った場合と同様に働きます.
昔の Caml-list の議論 https://caml-list.inria.narkive.com/WUIPH06Z/why-can-t-i-use-constructors-as-functions で,OCaml の設計者の Xavier Leroy が Neel Krishnaswami (彼もプログラミング言語の研究者)の質問にこう答えています.
Post by Krishnaswami, Neel
> I'm curious as to the reason why I can't use a datatype constructor
> fun add a b = fold Succ a b (* Use the Succ constructor as a funtion *)
> If I try something similar in Caml,
> # let add a b = fold (fun x -> Succ x) a b
The old Caml V3.1 implementation treated constructors as functions like SML.
In Caml Light, I chose to drop this equivalence for several reasons:
- Simplicity of the compiler. Internally, constructors are not
functions, and a special case is needed to transform Succ into
(fun x -> Succ x) when needed. This isn't hard, but remember that
Caml Light was really a minimal, stripped-down version of Caml.
- Constructors in Caml Light and OCaml really have an arity, e.g.
C of int * int is really a constructor with two integer arguments,
not a constructor taking one argument that is a pair. Hence, there
would be two ways to map the constructor C to a function:
fun (x,y) -> C(x,y)
or
fun x y -> C(x,y)
The former is more natural if you come from an SML background
(where constructors have 0 or 1 argument), but the latter fits better
the Caml Light / OCaml execution model, which favors curried
functions. By not treating constructors like functions, we avoid
having to choose...
- Code clarity. While using a constructor as a function is sometimes
convenient, I would argue it is often hard to read. Writing
"fun x -> Succ x" is more verbose, but easier to read, I think.
末尾再帰とループ
はい,末尾再帰で表現できます.
for i = e1 to e2 - 1 do
e3
done
は
(* loop : int -> unit *)
let rec loop i =
if i = e2 then
()
else begin
e3;
loop (i+1)
end
in
loop e1
という末尾再帰な関数loopで表現できますし,
while e1 do
e2
done
は
let rec loop b =
if b then begin
e2; loop e1
end else
()
という末尾再帰な関数loopで表現できます.
ブラウザで走る OCaml 処理系
簡単なプログラムを書き捨てるのであれば公式のOCaml Playgroundがあります.js_of_ocamlを使うともっといろいろできるのかもしれませんが,試したことがありません.何れにせよ,現時点ではあまりブラウザ上である程度大きいプログラムを書くのは難しいように思います.
ideoneというのもあるようで,ここで OCaml プログラムをこんなふうに書けるようです.
ヴァリアントからの値の取り出し
type nat = | Z | S of nat ;; let x=S Z;;のように
xを束縛した際にどのようにしてⅹのZにアクセスするのか教えていただきたいです。爆速入門では、定義の際にS of {?? : nat}という形で定義されていたので上記の例のアクセスの仕方がわかりませんでした。
パターンマッチを使うのが一番良いと思います.
let x = S Z in
match x with
| Z -> ...
| S Z -> ... (* (1) *)
| S x' -> ...
のようにすれば(1)と書いてある部分の式で Z のところにアクセスすることができます.
参照への参照
はい,できます.参照への参照もこんなふうに作れます.
# ref (ref 1);;
- : int ref ref = {contents = {contents = 1}}
中身は contents フィールドの中身が再び contents フィールドを持つレコードになっているような値になっていますね.
少し余談ですが,
type a = a ref
は参照への参照への参照への...と延々と続くような型になっていそうですが,このような型の定義は OCaml では許されません.
# type a = a ref;;
Error: The type abbreviation a is cyclic
が,OCaml インタプリタを ocaml -rectypes のように rectypes オプションをつけて起動すると定義することができます.
# type a = a ref;;
type a = a ref
では,このような a 型の値を作るにはどうしたらよいでしょうか.let recを使うと作ることができます.
# let rec (x:a ref) = ref x;;
val x : a = {contents = <cycle>}
# x;;
- : a = {contents = <cycle>}
# !x;;
- : a = {contents = <cycle>}
# !(!x);;
- : a = {contents = <cycle>}
# !(!(!(!x)));;
- : a = {contents = <cycle>}
指定した回数だけ参照の中を見る関数も書けます.
# let rec f n x = if n = 0 then x else f (n-1) !x;;
val f : int -> ('a ref as 'a) -> 'a = <fun>
# f 100 x;;
- : a = {contents = <cycle>}
fの型に現れている'a ref as 'a は「'a = 'a ref を満たすような 'a」という意味で,再帰型 (recursive type) と呼ばれます.
OCaml のための参考書
Ocamlを学ぶのによい参考書はありますか。
おすすめは五十嵐先生の教科書です.あるいは,計算機科学コースの実験3SWで使用している教科書もよいです.
あと,最近はこういう教科書も出ています.(まだ読んではいないのですが.)
Working directory を取得する方法
#useのコマンドを使うときに、現在のディレクトリが分からなくて困っていますが、現在のディレクトリを表示するコマンドはありますか?(#pwd;;などがあれば嬉しいです。)
答えになっているかわからないのですが,Sys.getcwd ()で現在のディレクトリを文字列として取得することができます.
未確定の単相型
ocamlのコードをかいている際にたまに出てくる’_weak1のような型(型なのか?)が何なのかきになった。
これは単相的な型変数です.OCaml 教科書の7.1.4節に解説してあるのですが,参照と多相性が共存する言語では,どのような場合に変数に多相型を与えて良いのかを注意深く設計しなければなりません.OCaml ではこのために値多相という方針を設けています.この教科書や講義でも解説しましたが,これは
let x = e in
...
のように let での束縛で式 e が評価が起こることのない構文的に値である場合のみにxが多相型になりうるというポリシーです.したがって
let f = fun x -> x in
(f 3, f true)
は,fに多相型 $\forall \alpha. \alpha \rightarrow \alpha$ が与えられるため,型付け可能となります.他方
let f = (fun x -> x) (fun x -> x) in
(f 3, f true)
は,(fun x -> x) (fun x -> x) が関数適用式であり構文上は値ではないため,fに多相型が与えられず型エラーとなります.
このときに
let f = (fun x -> x) (fun x -> x);;
を REPL に渡したときに返ってくる
val f : '_weak1 -> '_weak1 = <fun>
は,f は多相型ではないが,(fun x -> x) (fun x -> x) のみからは型を完全には決めることができないので,f の型は仮置きの型変数 '_weak1 を用いて '_weak1 -> '_weak1' と表されるということを言っています.この '_weak1' は単相的なので,以下の例が示すように,他の型と一度単一化されると,もはやその型としてしか使えません.
# let f = (fun x -> x) (fun x -> x);;
val f : '_weak1 -> '_weak1 = <fun>
# f 3;;
- : int = 3
# f;;
- : int -> int = <fun>
# f true;;
Error: This expression has type bool but an expression was expected of type
int
REPL で抽象データ型を pretty printing する方法
Ocamlにおいて、抽象データ型の値はすべて
の形で表現されるようですが、ここに(to_listのような関数を介するのではなく、式の値として)ユーザー側で定義した形式で表示させる方法はあるのでしょうか?
OCaml の REPL には #install_printer というディレクティブがあって,これを使うと多分できたように思います.REPLのマニュアルでinstall_printerという文字列を検索して,出てきたところを読んでみてください.使い方はOCamlverseにも載っているようです.
:: について
本テスト・クイズの問題4で使われている2重コロンはどういう意味なのでしょうか。
演算子 :: の意味は知らなかったので、五十嵐先生の Objective Caml 入門を読み直して復習しようと思います。インタプリタとコンパイラが「一行ずつ解釈」/「全体を翻訳」、という相対する概念であるという考え方を修正することが出来たのが今回最大の学びでした。
::はリストを作るときに使うコンストラクタです.
# 1 :: [];;
- : int list = [1]
# 1 :: 2 :: 3 :: [];;
- : int list = [1; 2; 3]
# 1 :: [2; 3; 4];;
- : int list = [1; 2; 3; 4]
から大体の動きを想像してもらうとありがたいです.
OCaml における破壊的代入
書き換え可能なデータ構造およびそれを再帰ヴァリアントに追加した場合の動作については習わなかったので、勉強用の資料があると嬉しいです。
例えば,https://kuis-isle3sw.github.io/IoPLMaterials/textbook/mltext.pdfの6章と7章あたりはどうでしょう.
OCaml における結合とその強さ
“関数定義式よりも関数適用式の方が結合が強いように書いたが合っているのか?AppExprの定義においてe1(左側の項)にAExprを、e2(右側の項)にAppExprを割り当てると右側を再帰的に読み取っていって右結合になるというのは割と目から鱗だった。他の箇所にも応用できそう。”
OCaml では fun f -> f 1 は
# fun f -> f 1;;
- : (int -> 'a) -> 'a = <fun>
のような出力がかえってきます.ここから (fun f -> f) 1 ではなく fun f -> (f 1) のように構文解析されていることがわかります.これにしたがって,関数適用式のほうが結合が強いようになっています.
中置演算子
(+);;に対して- : int -> int -> int = <fun>が返ってくるということについて、let sum a b= a+b;;に対しても同じように- : int -> int -> int = <fun>が返ってくるため、+はこのような形で2つ引数をとる関数と同じ型のものだと考えたのですが、+ 3 2のように関数と同じ形で使おうとするとエラーになりました。+というのは関数とは別にocamlの中で特別に扱われるものであって、+の型がint -> int -> int = <fun>のように表されるのは便宜上そう返すようにしているだけということなのでしょうか?また、中置演算子のように使える形で新たに関数をプログラマが定義することは可能なのでしょうか?
というより,(+) や ( * ) が中置演算子を普通の関数として使うための OCaml の記法と考える方がわかり良いかもしれません. OCaml には中置演算子や前置演算子として使えるシンボルやその結合や優先度があらかじめ定められています.これらのシンボルはStdlib モジュールで定義されていて,(+)や( * )はここで定義されています.Stdlib は特別なモジュールで,この中の定義はプログラム開始時点ですべて使えることになっています.たとえば
(+) 1 2
と入力して評価してみましょう.
(ところで,なぜ (*) ではなく ( * ) と書いているのでしょう.)
自分で演算子を定義することも可能で
# let rec (^^^) x n = if n = 0 then 1 else x * (x ^^^ (n-1));;
val ( ^^^ ) : int -> int -> int = <fun>
# 5 ^^^ 4;;
- : int = 625
みたいに(上記の演算子として使えるシンボルの範囲内で)自前の演算子を定義して使うことができます.
`|> 演算子
|>はどういう役割を持つ演算子なのでしょうか?
Stdlib で定義されている演算子です.一般にはパイプライン演算子と呼ばれています.説明を見ると
val (|>) : 'a -> ('a -> 'b) -> 'bReverse-application operator: x> f > g is exactly equivalent to g (f (x)). Left-associative operator, see Ocaml_operators for more information.
と書いてあります.つまり x |> f |> g のように書くと g (f x) と同じ意味です. |> の方がカッコが少ないのと,x という値が処理 f と処理 g をこの順番に通過するという感じがあって,こっちの方が読みやすい場合があったりします.組み込み等で注目されているElixirという言語でもこの演算子がフィーチャーされていますね.
例えば,以下のコード
String.split_on_char ' ' (String.uppercase_ascii (String.trim "Hello, world"))
は,パイプライン演算子を使うと
Hello, world " |> String.trim |> String.uppercase_ascii |> String.split_on_char ' '
と書き換えられます.この書き方だと処理の流れが文字の流れと同じ方向になって読みやすくなっていますね.
参照型
“ref型がすごい便利。いつも前の演習問題をして何時間もかけてわかりにくいコードで解けたと思ったら、あとから使えそうなコーディングが授業で使われる。損した気分になります。
一応 OCaml 演習で ref 型も解説してませんでしたっけ?それはそうと,ref 型をできるだけ使わずにプログラミングした方が関数型っぽいのと,デバッグが容易なコードになりがちだと思うのですが,どうですかね.
型変数
ocamlのインタプリタでは、多相的な型を返す際にa’、b’という表現を用いますが、z’まで型を使い切ってしまった後どのような表現が用いられるかは決まっているのでしょうか?
仕様で決まっているかどうかはわかりませんが,実装上は'a1, 'b1, …となっていたと思います.
Unused variable
・Warningが出ててもテストがうまくいけば良いのでしょうか?
[unused-var-strict]: unused variable~ がかなりでます。
本来は Warning はバグがある兆候なので無視すべきではありませんが,今回はテストが通ればいいです.Unused variable 例外は定義した変数が一度も使用されていないときに出ます.変数は普通使うから定義するものなので,これが出るということはなにか間違っている場合があります.(間違ってない場合も相当あるのですが.)
関数以外の再帰
MiniML4: 再帰的関数定義の導入のページに,「単純化のため再帰的定義の対象を関数に限定する」とあるが,関数以外の再帰とはどのようなものがあるのか.
例えば
type t = { head: int; tail: t}
let rec x = { head = 1; tail = x}
のようなのがあります.ところでこのxをインタプリタで評価するとちょっとおもしろいですよ.
言語処理系のバージョンアップについて
“授業資料などで、MiniML2→MiniML3→…のようにバージョンが上がっていくような感じがします。実際にOCaml初めその他のプログラミング言語にも「バージョン」という概念がありますが、例えばバージョンアップの時などは今私たちが課題でやったように、言語処理系の中身がいじられて機能が追加される…と言ったことが多いのでしょうか?”
はい,処理系のバージョンが上がると,それに付随していろいろな feature が追加されることはよくあります.たとえば,OCaml 5 ではマルチコア対応や,エフェクトハンドラと呼ばれる例外処理のお化けのような feature が追加されています.
OCaml での並行プログラミング
OCamlでマルチスレッドのプログラムを書くのが大変だという風な話(処理系がサポートしていない?)を噂程度に聞いたことがあるのですが、いま現在もOCamlでマルチスレッドのプログラミングを行うことはできないのでしょうか。
OCaml 5 ではマルチコアでのプログラムの実行がサポートされています.OCaml 5 はこれ以外にもエフェクトハンドラなど先進的な機構がサポートされているので,試してみてください.
参照型
ref型についてあまりよくわからなかった.C言語でのポインタに似ているように感じるが,C言語のポインタとOCamlのref型の間でどのような違いがあるのか気になった.
C言語のポインタと参照の一番の違いとしてはポインタ演算ができるかどうかという点があります.C言語だと
int a[10];
int *p = a;
のように p を配列 a の先頭を指すポインタにすると,p+5のようにして配列の途中を指すポインタを作ることができますが,参照はそのようなポインタ演算はできないようになっています.(これで答えになっているだろうか.)
なぜ rec?
“再帰関数の実装について、説明を読む限りは大まかなイメージができたと思ったのですが、実際にOCamlで実装するとなるとややこしいと思いました。OCamlと違ってC#やHaskellなどは再帰関数を定義するときにrecで区別することがないので実装が少し違うのか気になりました。”
rec で区別する理由は,OCaml で以下のようなイディオムを使うことが多いためです.
let rec fact n res = if n = 0 then res else fact (n-1) (n*res) in
let fact n = fact n 1 in
fact 5
1行目で定義しているfactは末尾再帰版の階乗関数です.2行目の右辺のfactは一行目で定義されたfactを指しています.これはシャドウイングによって,factを再定義しているわけです.もしletとlet recの区別がなく,全部再帰的定義とする場合,こういうイディオムを使うのは難しくなります.
なお,この辺の事情は古瀬淳さんのブログによくまとまっています.
無限ループ
無限ループするかどうかはスタックが限界まで到達して初めてインタプリタ側は把握できるということですか?
というより,プログラムが無限ループするかどうかを正しく判定するアルゴリズムは存在しないことが知られています.スタックが限界まで達したが計算を続けるといつか終わるのか,それとも本当に無限ループしているのかは自動的には判定できないわけです.この辺の話はそのうち授業中にやるかもしれません.
末尾再帰化
Ocamlについての質問になりますが、よくプログラムを実行する際に “Stack Overflow” になってしまいます。C++などではmalloc/newで回避できますが、Ocamlでは確か回避する記述は構造上ありませんでしたか。
関数を末尾再帰で書くのが一番簡単な解決策です.ちなみに,一般に再帰関数を「関数が返ったあとに行われるべき計算」を渡すスタイル(継続渡し)で書き直すと末尾再帰にできます.例えば
let rec fact n =
if n = 0 then
1
else
n * (fact (n - 1))
という関数は
let fact n =
let rec fact_cont n k =
if n = 0 then
k 1 (* (A) *)
else
fact_cont (n-1) (fun r -> k (n * r)) (* (B) *)
in
fact_cont n (fun x -> x) (* (C) *)
と書き直すと末尾再帰になっています.ここで fact_cont に渡されている k : int -> int は,「今の呼び出しが終わったあとに,その計算結果を使ってやるべき計算」を表す関数です.(この「この後の計算」のことを継続 (continuation) と呼びます.)実際に (A) の行ではこの呼び出しで計算した結果(すなわち n = 0 のときの階乗 1)をその後の計算 k に渡しています.(B) の行では,この呼出で計算した結果(すなわち n-1 の階乗)が求まったら,その後 r をその値に束縛して n をかけて n の階乗が求めた上で,それをその後の計算を表す関数 k に渡しています.こうすると関数が末尾再帰になって,スタックを消費しなくなります.(代わりに (B) でクロージャを作っており,これを確保する領域を消費しています.これは挙げてもらった malloc/free でメモリを使うことに似ていますね.)
この例に関しては,継続で行うべき計算は実際のところここまでの計算で求めた整数一個で余すことなく表現することができます.そのため,いちいちクロージャを作る必要はなく
let fact n =
let rec fact_cont n res =
if n = 0 then
res (* (A) *)
else
fact_cont (n-1) (n * res) (* (B) *)
in
fact_cont n 1 (* (C) *)
という実装が可能となるわけです.
open
問題5のコードの最初の部分にある"open List "は何をしているのですか。
これは List モジュールで定義されている関数を,これ以降 List. をつけて呼び出さなくても良いという記法です.List モジュールの中には,例えばリストの長さを計算する関数 length が定義されていますが,これを呼び出すためには List.length のようにモジール名を関数の前につける必要があります.これを length と単に書くだけで呼び出せるようにするのが open List のやっていることです.便利なのですが,複数のモジュールで length という関数が定義されていたときにどの関数が呼び出されるかがわかりにくくなるので,使用は最小限に留めるのが吉.
あるいは,let open List in ... という構文を使うと,... の中だけで List モジュールが open されるため,List がファイル全体で open されるよりも良いですね.
OCaml の print 関数
OCaml組み込みのprint関数が多相型ではなく、一つ一つの型に対して一々別の関数で実装されているのは何故なのでしょうか
値の出力の仕方が型によって違うからです.整数を表すデータであるか,文字列を表すデータであるかによって,データをどのように整形して出力するかが異なってきますよね.これは加算の実装が型によって異なるために + と +. とが区別されているのとパラレルで,アドホック多相をやる必要があります.そのため,OCaml では型ごとに組み込みの出力関数を用意しています.
なお,Printf モジュールや Foramt モジュールで定義されている関数(というかフォーマッタ文字列)は,ちょっと特殊な型推論をすることで,単一の printf 関数にフォーマット文字列を渡して,その文字列によって様々な型の値を出力できるようになっています.このブログ記事やこのブログ記事に詳しいです.
関数適用と結合
repr S(S(S(S(Z))))とすると
this function has type nat-> int it is applied to too many arguments; maybe you forgot a';'とでてきたのですがどういうことですか。
これは OCaml のハマりどころの一つです.repr (S(S(S(S(Z))))) のようにカッコを引数の周りにつけると解決するはずです.
repr S(S(S(S(Z)))) は OCaml の文法では (repr S) (S(S(S(Z)))) のように解釈されています.すなわち,1引数関数のreprを2つの値に適用しようとしていると解釈されているので,このようなエラーが出ているわけです.
else
例えば,
let x = ref 0;; let set v = x := v;;という関数があったとき,
set vの結果はunit型なのでelse文を省略してif (!x = 0) then set 1;;と書けますが,
let set_ v = x := v; v;;と,値を代入したついでにその値を返すような関数の場合,
set_ vの結果はint型なのでif (!x = 0) then set_ 1;;と書くとエラーになります.このような関数をelse文なしで実行する方法はありますか.
ignoreという,値を無視する関数があります.型は'a -> unitです.これを使うと
# if (!x = 0) then ignore(set_ 1);;
- : unit = ()
のように書けます.無視しようとする値はignoreに渡すというのは,覚えておくと良いです.
let () = ...
配布コードの内のmain.mlのlet ()の()は関数名ですか?それとも何か特別な記法の一つなのですか。()の部分を変化させてビルドしたら通らなかったので少し不思議に思いました。
この()は実はパターンです.let x = ...のxの場所には,実はmatch式で使うようなパターンを書くことができます.(例えばlet (x,y) = ... とか let Hoge y = ... とか書くことができます.)()はunit型の値にのみマッチするパターンです.したがって,let () = ...は...のところを評価して,その評価結果が()であることをチェックする,という挙動になります....の場所がunit型であることが分かっているときには,このように明示的にlet () = ...と書く方が堅牢です.(let _ = ...と書いても多分コンパイルは通るのですが,...の場所を間違って編集してunit型以外の式にしてしまったとしてもエラーを知らせてくれなくなります.)
OCaml における配列
“OCaml でランダムアクセスをしたい場合は array を使う (https://ocaml.org/docs/data-structures-comparison) ようなのですが、再帰的な処理を多く行う場合はあまり用いられないのでしょうか?また、OCaml で nth を定義するときに線形時間かかっていたので驚いたのですが、nth を使う機会は頻繁にあったりするのでしょうか?”
リストについてはn番目の要素を参照する際にnに比例した時間がかかります.ただ,リストは再帰的に定義されたデータ型なので,再帰関数で処理を行いやすいという利点があります.どの要素にもO(1)でアクセスできる必要がある場合には配列を使う必要がありますが,こちらは再帰で書くと少し不格好になります.というわけで,用途によって使い分けることになるなあという感じがします.
OCaml における比較演算子
“SW3の実験でこの授業で学んだ束縛やクロージャの話を元にOcamlを改めて学ぶのが思いの外楽しいです。本授業におけるMinimlでは不等号の両辺はint型でなければエラーが出ますが、OCaml(および他の言語でも?)では文字列同士でも評価できると知って驚きました。TAさんには評価方法は辞書順に行なっていると伺いましたが、ASCIIコードを参照して評価しているのでしょうか?少し気になりました。”
比較演算子は,適用される型によって異なる実装による比較が行われます.OCaml のプログラムではこのようなことはできないのですが,比較演算子については実装を C プログラムで書くことでこれを可能にしています.(C と OCaml を組み合わせる方法はここを読んでみてください.)ライブラリの説明では
Structural ordering functions. These functions coincide with the usual orderings over integers, characters, strings, byte sequences and floating-point numbers, and extend them to a total ordering over all types. The ordering is compatible with ( = ). As in the case of ( = ), mutable structures are compared by contents. Comparison between functional values raises Invalid_argument. Comparison between cyclic structures may not terminate. Left-associative operator, see Ocaml_operators for more information.
のように,どのように比較されるかが明示化されていませんが,実装では辞書式順序になっているようです.
インタプリタについて
遅延評価と if 式
また、一つ質問なのですが、課題1のExercise 3.9について、OCamlでは評価戦略がcall by valueであるためにif式を関数で書けないと考えたのですが、では評価戦略がcall by needであるHaskellでは関数でif式を書くことができるのでしょうか?お答えいただけると幸いです。”
可能です.こんなかんじ.
ghci> myif b e1 e2 = if b then e1 else e2
ghci> fact n = myif (n==0) 1 (n*(fact (n-1)))
ghci> (fact 0, fact 5)
(1,120)
バッチインタプリタ
Exercise3.3.3について、バッチインタプリンタが何かわかりません。例えば、以下のプログラム
let x = 2 ;; x;; true;;が書かれたファイルmain.mlがあったとして、これを
miniml main.mlにより、実行したときにval x : int = 2 - : int = 2 - : bool = trueを出力し、環境にxを束縛すればよいということでしょうか?
はい,そういうことです.「バッチ」とは「塊」という意味で.いくつかの宣言が塊になってやってきても処理できるように改造してくださいという意味です.
menhir について
Menhirについて質問です。構文解析器が与えられたトークン列を生成するための規則を順番に解析していき、最終的に規則列が判明した後に還元時アクションを実行して開始記号の属性を計算する、とありますが、開始記号の属性の計算は何のために行こなうのでしょうか。
開始記号の属性が,構文解析器がプログラム側に返す値となります.なので,開始記号の属性としてプログラム全体の AST を返してやる必要があります.
ocamllex のエントリポイント
lexerの部分のエントリポイントの仕組みがいまいちわかりませんでした。
Real World OCamlの “Lexing Rules” と “Recursive Rules” の節を読むと少しわかりやすいかもしれません.読んでみてください.
ルール中に直接に文字列を書けるか
parserでSEMISEIMIやEQなどのトークンを使っていたが、直接;;や=ではだめなのですか
字句解析と構文解析のステージが分かれているという点は大丈夫でしょうか.lexer.mll は字句解析のためのファイルで,これを元に生成された字句解析器が入力をトークンの列に変換します.parser.mlyによって生成される構文解析器は,このトークンの列を抽象構文木に変換します.ですので,parser.mly にはトークンである SEMISEMI や EQ が書かれているわけです.もしよくわからなければ第1回の講義をもう一回見返してみると良いかもしれません.
ですが,世の中には.mlyファイルに直接文字列や正則表現を書ける構文解析器生成ツールもたしかあったと思います.(そのようなツールでは,直接書いたこれらの情報を implicit にトークンとして扱うはずです.)Menhir は今ざっとマニュアルを見ましたが,そういう機能はないようです.
lexer
lexerについて、3.2.4から正則文法よりは広い文法のクラスを表現できることはわかりますが、任意の文法を表現することはできるのでしょうか。またもしlexerに表現できない文法クラスが存在する場合、そのような文法クラスを表現できないことによって何らかの不都合が発生することはないのでしょうか。
ocamllex がどの程度の文法クラスまでを表現できるかは,あまり自信を持った答えがありません.パターンの部分に書けるのは正則言語で,これにルールの再帰呼び出しを使ってスタックを表現できるので,多分文脈自由言語程度なんじゃないかなと思います.
文脈自由言語を超えた文法クラス(例えばチューリングマシンで認識可能な言語)は多分扱えないと思うのですが,プログラム中の字句にあまり複雑なルールを設けることは実際には無いと思うので,多分問題はないと思います.(例えば,変数として使えるのは a2, a3, b5, c7, grothendieck57 のように素数で終わる識別子のみとする,みたいな言語作りたくならないですよね.)(いや作りたいかも.)
Python における環境
Pythonなど他言語のインタプリタを実行する際にも変数の宣言や代入が行われるときは内部的には環境という形で変数の束縛情報の保持/更新がなされているのだろうか?”
「環境」という名前で呼ばれているかはわからないですが,変数の型情報や値の情報は管理してると思います.(でないと,変数の値を参照することができない!)
なぜプログラミング言語の構文定義に文脈自由文法が使われるか
プログラミング言語のシンタックスを定義するにあたって、文脈自由文法以外(文脈依存など)を用いるとまずい具体的な理由を知りたいです。
まずいわけではないのですが,文脈自由文法(のあるサブクラス)の構文解析アルゴリズムの性能がめっちゃいいというのが理由としてあるんじゃないかなと思います.あと,AST が直感的なのもあるのかもしれません.(文脈の情報を木でエンコードするのは結構大変そう.)
parser.mly について
構文の定義について
“Parser.mlyの文法規則の記述の部分の質問です。構文解析器はトークン列から抽象構文木に変換するものだと認識しているのですが、その場合規則の最初はトークン列のTRUE SEMISEMIが来ると思ったのですが、なぜExpr SEMISEMIから開始しているのでしょうか”
TRUE SEMISEMI だと,true;; というプログラムしか構文解析できなくなってしまいます.Expr SEMISEMI にしていれば,非終端記号 Expr から導出されるものが SEMISEMI の前に来れます.parser.mly の定義を丁寧に追うと,Expr から TRUE が導出できるのがわかると思います.
Parser や Lexer の内部動作の確認方法
- ex3_2_2 の実装にあたって:実際生成された Parser や Lexer の signature や内部の論理はどこかで確認できますか?VS Code の拡張機能を利用すれば signature が確認できるのですが、実際手作業で確認したい場合どうすればよいのでしょうか。
一応 parser.ml や lexer.ml が実装になっていますが,これはなかなか読みにくいと思います.以下のようにするともう少し読みやすいような記述が生成できるかもしれません.
dune-projectファイルの(lang dune 1.6)を(lang dune 3.0)に,(using menhir 2.0)を(using menhir 2.1)に置き換える.duneファイルの
(env
(dev
(flags
(:standard -warn-error -A -w -39)
)))
を
(env
(dev
(menhir_flags --dump --explain)
(flags
(:standard -warn-error -A -w -39)
)))
に変更3. dune runtest を実行.4. _build/default/src/parser.automaton をエディタで開く.
(うまく行かなったら Slack で知らせてください.)
曖昧性について
Parser.mlyを拡張していくにつれて、文法が曖昧性をもたないことに自信がなくなってきました。リテラルと中置演算子だけで構成されているトークン列に関しては現在のやり方でうまく優先順位が付けられていることが証明できましたが、let式やif式、fun式などが追加されていくと不安になります。
文法が曖昧であるときには, shift/reduce conflict とか, reudce/reduce conflict とかいう警告が出ます.これを読み飛ばさないことが肝要です.
優先順位や結合の定義の仕方
授業でparser.mlyでFunExprなどは書く位置が大事と言ってた気がするのですが、書く位置というのは、プログラムの書く位置ではなく、Pexer,Mexerなどの適用順ということでしょうか?
はい,そうです.これによって演算子の優先順位や結合を決めています.
let () = ...
main.ml の各行末に ;; を入れ、 let () = を削除しても普通に動いたのですが、なぜここで let () = のような書き方をしているのでしょうか。
いくつか理由はあると思いますが
- 式の評価結果の型が unit であることを強制するため.
- どこが main の式であるかを見た目わかりやすくするため.が大きいかなと思います.
複数の定義
MiniMLで今後”i”や”v”などを変数として宣言することはできないのでしょうか?
let宣言を実装すれば可能です.普通の OCaml と同様に,
# let i = 100;;
のように入力するとiが100に再定義されます.
MiniML インタプリタのモジュール構成について
”- モジュール周りに対する理解が浅いのですが、例えば Eval や Parser などといったモジュールがあること(つまりそれらのモジュールの signature?)はどこで定義されているのですか?プログラムで
open EvalやEval.Errorなどの記述が可能になっているのでどこかに定義されていると思うのですが、見つかりませんでした…
モジュール Eval の実装は eval.ml に,インターフェイスは eval.mli に記述されています.ファイル名の拡張子を除いた部分の最初の文字を大文字にしたものがモジュール名になる,という規則になっています.
テストにおける undef について
- ex3_2_3 の実装にあたって:undef はどのように定義されていたのでしょうか?テストが通るように
b1 && undef = b1, b1 || undef = true, undef && undef = undef || undef = undefという評価にしたのですが、実際はどういう想定でしょうか?”
undef は評価した瞬間にエラーになるように評価してほしいです.そのためには,false && undef は undef を評価することなく false を返し,ture || undef は undef を評価することなく true を返さなければならりません.OCaml でも実際にそのように実装されているはず.
undef
3.2.3において、テストを実行したところundefというものが現れているテストケースで落ちてしまったのですが、このundefというものはocamlに標準で存在するのでしょうか、あるいは自ら新たに意味を定義する必要があるのでしょうか。
実験3FAQのQ3-2とQ3-3を読んでみてください.
undefはOCamlには存在しないのですが,テスト中の意図は評価するとエラーになる何らかの式です.(実際にテスト中ではundefという変数は定義されていないため,評価すると Variable not found で落ちてしまいます.OCamlでは型推論を行った時点でundefという定義されていない変数が参照されていることが検知されて型推論に失敗しますが,型推論を行っていないMiniMLでは,undefが未定義ということは,評価を行う時点で初めて分かります.)e1 && e2はe1がfalseになった段階で,e1 || e2はe1がtrueになった時点でe2を評価することなく結果を返します.
関数閉包とプロトタイプ宣言
関数閉包の話は他のプログラミング言語におけるプロトタイプ宣言の実装にも必要となってくるのでしょうか?
プロトタイプ宣言ではあまり必要ではなくて,むしろ実行時に関数を表す値をどのように表現するかに関わってきます.プロトタイプ宣言はむしろ関数の型を宣言する方法に近いかと.
再帰関数の実装方法
静的束縛関する質問です。関数を表す値に環境を入れるという方法を取るのではなく、関数を定義したときにその定義式に現れる自由変数を評価し、即値として関数に入れておく、という考え方はよくないのでしょうか。例えば問題 2 で例として使ったコードにおいて:
let f = let x = 2 in fun y -> x in f false;;関数 f は (id, body, env) = (““f””, FunExp(““y””, Var ““x””), [(““x””, 2), ……]) というように表されていると思うのですが、定義の時点で関数の本体式 y -> x を、束縛変数 y を除いた部分だけ評価してしまって y -> 2 として、(id, body) = (““f””, FunExp(““y””, ILit 2)) と保存してしまっても問題ないかと思っております。
はい,これはよい気づきで,再帰関数の扱いを工夫すればMiniMLくらいであればうまくいくかもしれないのですが,一般にはうまくいきません.挙げてもらった例では x の束縛先が 3 というすでに値になっている式なので置き換えてしまう方法で上手くいくのですが,
let x = print_string "hoge" in
let f () = (x, x) in
f ()
のようなプログラムを考えて見てください.このプログラムを OCaml に入力すると,hoge という文字列が一回だけ実行されますが,f中のxを単純に置き換えると
let f () = (print_string "hoge", print_string "hoge") in
となってしまい,これを呼ぶと hoge が2回出力されてしまいます.これでは意味が変わってしまっていますね.
また,関数閉包中に同じ変数が何度も現れており,その変数の束縛先が巨大な値だったりすると,値を全部コピーする必要があって,メモリ効率的に問題があります.
関数閉包に含むべき変数
環境のキャプチャはクロージャ本体に現れる自由変数だけで良い思った。現実では環境のコピーにどれくらいオーバーヘッドが発生するか気になりました。
はい,クロージャ本体に現れる自由変数のみでよいです.現実のオーバーヘッドは計測してみないとわかりませんが,スコープ内の変数の数がクロージャ内の自由変数よりも圧倒的に多い場合には,クロージャ内の自由変数だけをコピーする方が効率的でしょう.
関数の定義時に変数をその値に置き換えれば関数閉包はいらない?
関数作成時の環境をまるごとクロージャとして保存したのでは,関数で参照しない変数の情報まで保存することになり,無駄な情報が多すぎるので,関数の定義時に変数をその値に置き換えるほうが効率的ではないかと思った.例えば,let x = 3 in let f () = print_int x in let x = 4 in f ()において,fを定義した時点で,xに3を代入して
let f () = print_int 3 inと解釈してしまったほうが良いのではないか.また,このようにした場合,何か問題が起きるのだろうか.
まず,環境をまるごとクロージャとして保存するのは無駄というのは正しいです.なので,実際には関数中で参照しうる変数に関する情報のみをクロージャに保存しておくと良いかもしれません.
で,
関数の定義時に変数をその値に置き換えるほうが効率的ではないか
は良い視点なのですが,実はこれでは一般にはうまくいきません.挙げてもらった例では x の束縛先が 3 というすでに値になっている式なので置き換えてしまう方法で上手くいくのですが,
let x = (fun () -> print_string "hoge") in
let f () = (x (), x ()) in
f ()
のようなプログラムを考えて見てください.このプログラムを OCaml に入力すると,hoge という文字列が一回だけ実行されますが,f中のxを単純に置き換えると
let f () = (print_string "hoge", print_string "hoge") in
となってしまい,これを呼ぶと hoge が2回出力されてしまいます.これでは意味が変わってしまっていますね.
Environment.t
miniml3の関数の導入のところでeval.ml内の、type exval = IntV of int | BoolV of bool | ProcV of id * exp * dnval Environment.tの dnval Environment.tがクロージャが作成された時点の環境をデータ構造に含めるためのものだということは分かるのですが、この文がどういう意味合いを持っているのかが分からないです。
型exvalの定義にProVを加える際に、単にidexpEnvironment.tとするのではなくidexp dnval Environment.t のようにdnvalを書く必要がある理由がよく分かりませんでした。
Environment.t は型引数を一つ取る型として定義されています.なので,Environment.tだけでは型になっておらず,引数となる型であるdnvalを与えて初めて型となります.「プログラミング言語」講義資料の多相的二分木 in OCaml のところを読んでみるとより分かるかもしれません.
少し詳しく述べると,'a tは環境(すなわち変数の'a型の値への束縛を表現するデータこ構造)を表す型です.この.mliファイルでは,tが具体的にどういう型かは書かれていません.すなわち,tがどのような型で実装されているかが隠蔽されています.(environment.mlでは'a tが(string * 'a) listで実装されていることが書かれていますが,.mliでは隠蔽されているので,Environmentモジュールを使用する際には'a t型の値を(string * 'a) list型の値として使うことができません.)これにより,environment.mlファイル中で'a t型の実装を変更したとしても,Environmentモジュールを使用している側の実装を変更する必要はありません.
denoted value と expressed value の違い
eval.mlで定義されているdnvalという型はなんの目的で用意されたものですか?
これは denoted value の略です.変数が指す (denote する) 値ということです.教科書を見てもらうとよいかなと思います.講義中にも少し言及したので,必要であればそちらも.(どの回だったっけ…)
OCaml では一旦変数を束縛すると,その束縛先を変更することはできません.他方,C言語では変更することができます.
int main(int argc, char **argv) {
int x = 0;
x = x + 1; /* (A) */
return 0;
}
したがって,xは変更可能なデータ,すなわち OCaml で言うところの参照っぽいものに束縛されているはずです.他方,上記ソースコードの (A) の行では,=の右辺でxが評価されていますが,その評価結果は(参照ではなく)現在参照に入っている値です.すなわち,xが束縛されている先の値 (denoted value) は参照であるのに,xを評価して出てくる値 (expressed value) は参照ではないということが起こっています.言語によってはこのような区別をする必要があるので,今回のソースコードでは分けています.
実際に,今回のソースコードでは環境は変数の dnval への束縛であるのに対して,eval_expで返ってくる評価結果はexvalになっています.
関数閉包を使わなくてもよい関数
関数作成時にクロージャを作るのはまあまあオーバーヘッドがかかる処理なのかなと思ったので、実用的なプログラミング言語において環境をクロージャに含めなくても実行できる関数はクロージャが必要な関数と区別されているのかなと気になりました。
少なくともコンパイラではクロージャを作らなくてよい場合(すなわち,クロージャを作らず,関数定義が書かれているラベルにジャンプするだけで良い場合)はクロージャを作らないように最適化されている場合が多いかなと思います.ミニなコンパイラですが,住井先生のMinCamlコンパイラもそのように実装されていた記憶があります.
^[[C とは
minimlの標準入力で左ボタンおしたら下記のような文字が入力されます。これはなんなんでしょうか。
# ^[[C"
ターミナルが左ボタンに対応付けられたコードを表示する際の特殊な文字です.この stackoverflowの記事がよくまとまっています.このコードを受け取ったときにカーソルを実際に左に動かす機能がインタプリタに実装されていないため,このような文字が表示されます. rlwrap dune exec miniml とかで起動すると左キーでちゃんとカーソルが左に動くかもしれない.
...
Exercise 3.4.3のfun x1 … xn -> …やlet f x1 … xn = …が分かりません。ピリオド三つでどのような意味になるのでしょうか
すみません,...はそのままインタプリタに与えるシンボルではなく,何かが略されていることを表している(メタな)シンボルです.なので, ... のところに変数の列や式を書いた任意の式,例えば fun x y -> x + y とか let f x y = x + y 等の式をサポートしなさい,というのがここでの意図です.
OCaml を使ったらよい?
miniMLを記述するのにOCamlを用いることに違和感を覚えました。OCamlを用いてminiMLを拡張しOCamlのような言語を作るのであれば、はじめからOCamlを使えばよいのではないかと思いました。
今回の実験の範囲だと,確かに OCaml 最初から使えばいいじゃんとなりますが,MiniMLじゃなくて別の言語を作ることを想像すると意義が少しはあると思ってもらえると思います.(思ってもらえるといいなあ.)あと,車輪の再発明も楽しくないですか?
もう少し真面目な話としては,今回の話は「miniMLを拡張しOCamlのような言語を作る」では必ずしもないです.OCaml にないプリミティブを追加したり,OCamlと違う意味論をMiniMLに追加する,みたいな実験が教科書中に出てきます.たとえば,関数値の自由変数の値を,OCaml のように定義時に決めるのではなく,適用時に決めるようにする動的束縛を実装する問題3.4.5とかがそうです.こういうのを実装して MiniMLをだんだん OCaml と違う言語に拡張していく過程を楽しんでいただければと思います.
ProcV
ProcV は何の略でしょうか? 既出だったらすみません、
Procedure value のつもりです.
自由変数
ocamlにおいて自由変数というのは特定のスコープの中で自由ということで、プログラム全体で見るとどこかしらで束縛されているという理解で良いのしょうか?
はい,そういうことですね.プログラム全体で自由な変数があった場合,Unbound value であるというエラーが出ます.
なお,外部ライブラリを使うプログラムを書く場合は,その外部ライブラリで定義されている型や関数や変数が自分のプログラムにとっては自由変数になります.(例えば,Java で System.out.println メソッドを使うプログラムを書いた場合,自分で System クラスや,out というオブジェクトや,println というメソッドを定義するわけではないので,これらは自分のプログラムにとっては自由な名前になります.)その場合でも,ビルド時や実行時には外部ライブラリの実装とのリンクが行われて,そこで自由変数が自由でなくなることがほとんどです.
CUI とは
cui.mlのcuiは何の略でしょうか?
“Character User Interface” の略で,シェルなどのように文字ベースのユーザインターフェイスのことを表す一般的な用語です.類語には “Graphical User Interface” (GUI) があります.こっちは視覚的なユーザインターフェイスで,タップやマウス等での入力を受け付けるものなどがあります.
なぜ型変数は前置なのか
Environmentの型について、type ‘a t = …というのは型の名前がtで型変数’aを取りうるということだと思うのですが、関数の場合だとたとえばlet 関数名 仮引数 = fun… と書くのが一般的だと思いますが type t ‘a としても大丈夫なのでしょうか?
これは OCaml の構文の不思議なところの一つなのですが,OCaml では型引数は前置 (すなわち,'a tと書かねばならずt 'aと書いてはならない) で,関数に与える引数は後置 (すなわち,関数 f に 3 を引数として与えるときには f 3 と書かねばならず,3 f と書いてはならない) と決まっています.これまでも整数への参照を表す int ref 型や整数のリストを表す int list 型が出てきましたが,これも型引数 int が前置されていますね.
OCaml の REPL
Ubuntu上でocamlを実行しているのですが、1個上の実行をもう一回実行したいときに上ボタンを押しても
# ^[[Aのような文字列が表示されます。意図通りになるようにすることは可能ですか?
いくつか方法があるのですが,一番簡単なのは utop という高機能な OCaml の REPL を使うことです. opam install utop をして, ocaml を実行する代わりに utop を実行してみてください.使い方は普通の REPL と同じですが,上キーとかが使えます.
パターン
パターンマッチングを用いた関数の引数は型そのものなのかそういう型を持った値なのかどちらでしょうか。また、パターンマッチングで使えるのはヴァリアント型だけなのでしょうか。つまり、例えば
intやboolなどの基本型を用いてmatch x with | int -> 0 | bool -> int -> 1 ;;のような書き方も可能なのでしょうか(これではパターンが尽くせていなくてエラーが出そうですが、そもそもパターンを尽くしているとはどういうことなのかもついでに教えていただけると嬉しいです)
OCaml入門の3.2.2節と5.2節に目をまず通してみてください.
OCamlの文法でパターンとして書けるものが決められています.BNFを読むよりはその後のいろいろなパターンの類型を読むのがおすすめです.
let is_empty l =
match l with [] -> true | _ :: _ -> false
のように空リストにマッチするパターンや,空でないリストにマッチするパターンが書けたりします.また,
let string_to_bool s =
match s with
| "true" -> true
| "false" -> false
| _ -> raise (Invalid_argument "string_to_bool")
のように,定数にマッチするパターンを書くことも可能です.その他いろいろあるのですが,型にマッチさせることはできません.型はパターンではないからです.
let plus x y =
match typeof(x), typeof(y) with
| int, int -> x + y
| float, float -> x +. y
| int, float -> (float_of_int x) +. y
| float, int -> x +. (float_of_int y)
のように書けると便利かもしれないですけどねー.
コンストラクタ
また、上の質問と繋がりますがヴァリアント型の定義の例えばtype furikake = Shake Katsuo Nori;; における「Nori」や「Shake」の部分はこれはそもそも何なのでしょうか。これらは「型」なのか「値」なのか「式」なのか、それとも全く新しい別の何かなのでしょうか。
多分こっちの例の方がわかりやすいかもです.
type nat = Zero | Succ of nat
この Zero や Succ は「コンストラクタ」と呼ばれるもので,必要な値を引数にとって式を構築するものです.Zeroは引数が0個,Succはnat型の引数を一個取るので,
Zero
Succ(Zero)
Succ(Succ(Zero))
等が式となります.コンストラクタは値を構築するためのタグみたいなもので,これ自体が何らかの計算をするわけではないです.(これで少し説明になっているといいのですが.もし分からなかったらまた質問してください.)
末尾再帰
リストは最初に中身の個数を明示しなくていいのが感動しました。末尾再帰に関してですが、コンパイラやインタプリタを通して最適化をしてくれることはないのでしょうか。
OCaml コンパイラは(そしていろんな言語のコンパイラは)末尾再帰関数の場合とそうでない場合で関数の実装方法を変えています.具体的には,末尾再帰関数の場合は再帰呼び出しの際にスタックに返ってくる場所の情報を記録するという処理を行わず,ジャンプ命令によって再帰呼び出しとリターンを実装することができます.今はなんのことかわからないかもですが,コンパイラのところでもう少し詳しく説明します.
カリー化
正直カリー化で複数段階に関数を分ける有用性が感じられなかったのですが、どういう場合に使われるのですか。
どのくらい納得いくかわかりませんが,以下のようなことはできます.
# List.map ((+) 1) [1; 2; 3; 4];;
- : int list = [2; 3; 4; 5]
(+) 1 は足し算を行う2引数関数 (+) に引数 1 を一個だけ適用した関数です. (+) の型は int -> int -> int なので, (+) 1 の型は int -> int になります.List.map f l はリスト l の要素それぞれに f を適用した結果を返す関数なのですが,このfのところに(+) 1を渡すと,「受け取った値に 1 を加えて返す関数」をList.mapの第1引数に与えていることになります.なので,上のプログラムでは[1;2;3;4]のそれぞれの要素に1を加えた結果が返ってきているわけです.
このように複数引数を取る関数に一部の引数を渡すということが簡便にできるのは,カリー化されているおかげと言えるかなと思います.
+と+.
型推論などはするが、型の種類によって演算子が異なるのは面白いなと感じた。エラーになるのであれば初めからfloat 同士の演算なら+ を+. に勝手に読み替える、もしくは初めから(内部の実装や処理には変化があるが)表記方法をそろえればよかったのではと感じた。何か理由があるのだろうか。
このようなオーバーローディングはアドホック多相と呼ばれる多相性の一種です.これに対して,OCaml の fun x -> x 等の関数に 'a -> 'a のような型がつく多相性はパラメトリック多相と呼ばれます.
OCaml ではアドホック多相のサポートがありません.一般にアドホック多相を安全に言語に導入するためには,(1) 実行時の値の表現を工夫するか,(2) 実行時の値の表現は変えずに型推論アルゴリズムを工夫するかのいずれかが必要となります.(1) は実行時のオーバーヘッドの問題があり,(2) は型推論アルゴリズムが複雑になるという問題があります.例えば (2) の設計方針に従って + を int -> int -> int と float -> float -> float の両方としてオーバーロードする(すなわち,型に応じて整数の加算と浮動小数の加算のいずれかを + の適切な実装として選ぶ)ためには,e1 + e2 という式の型推論を行ったときに
e1もe2もintであればint -> int -> intの+を使うe1もe2もfloatであればfloat -> float -> floatの+を使うe1がintでe2がfloatであれば,e1をfloatに変換した上で,float -> float -> floatの+を使うe2がintでe1がfloatであれば,e2をfloatに変換した上で,float -> float -> floatの+を使う
のように型推論時にコード変換を行うことになります.(多分.)普通の型推論に比べてだいぶめんどくさそうですね.
また,+を文字列の連結を行う演算子として,string -> string -> stringにもオーバーロードしてしまった場合,3 + 4.0を浮動小数7.0にするのか文字列"34.0"にするのか,文字列"3.04.0"にするのかみたいな論点が生じえます.こういうこともきっちり決めるのも結構大変そうですね.
というわけで,型推論を軽量に,かつ実行時の効率をある程度良くして,かつ言語設計をわかりやすくするためには,OCaml ではアドホック多相は入れずにユーザに+と+.を区別させるという設計になっているのではないかなと想像しています.
なお,SML#にはアドホック多相のサポートがあります.
eval_decl
eval.ml のeval_declの役割がよくわかりません。eval_expなどでは、式が評価されて適切な値が返されているとわかるのですが、このeval_declでは何を評価して何を返しているのかうまく理解することができませんでした。
eval_decl は OCaml での ;; がついた文を表しています.あまり明示的には説明していませんが,OCaml では
# 3 + 4;;
のように,式を評価する文を書いたり,
let x = 3;;
のように,変数を定義する文を書いたりできます.前者の文は eval_exp を使って得た評価結果を画面に表示するだけなのですが,後者は REPL で使う環境に x の 3 への束縛を追加するという効果があり,普通の式の評価とは違っているため,eval_exp と eval_decl を分けています.
parser.mly や lexer.mll はどういう言語で書いてある?
parserやlexerがどうしてあのように書けるのかがわかりません.OCamlのプログラムではないのでしょうか?
ocamllex や menhir は通常の OCaml とは文法の異なる .mll ファイルや .mly ファイルを OCaml のプログラムに変換する処理系です.すなわち,.mll や .mly 自体は OCaml プログラムではありません.しかし,これらから生成されるプログラムは通常の OCaml プログラムです.実際に演習用リポジトリで dune build をして _build/default/src の中の parser.mli や parser.ml や lexer.ml を見てみると,(人間には理解しにくいですが)通常の OCaml プログラムになっています.
LetRecExp の型について
“Exercise 3.5.1 の実装ですが、LetRecExp などを
id * id * exp * expと定義するのではなく、id * exp * expと定義し、真ん中の exp が FunExp であることを parser 側で要請する、という実装をしてみました。少し手間ではありましたが、こうしたほうがきれいかと考えました。あえてid * id * exp * expとしている理由を、もしあれば教えてください。自分で実装にあたって一つ気付いたのは、eval.ml の実装で現在の環境に (id, dummyenv) を拡張する際に、結局ProcV (para, exp1, dummyenv)を書かざるを得なくて (真ん中の exp を eval_exp のパターンマッチに任せる、という実装が無理)、FunExp の良さを活かせないという点でした。”
これはありうるのですが,真ん中の exp が関数であることを exp 型のレベルで強制したいという理由で現在の実装になっています.Parser で強制するのは手なのですが,exp型の値が(手で直接書くこともできるので) parser で生成されたもののみとは限らないという問題があります.関数であることを強制しない場合は,let rec f = f in f のような式をいちいち排除する必要があり,ちょっと面倒です.(OCaml はご提案頂いた方式で実装されていると思うのですが,実際に再帰的定義の右側に何が来てよいかのチェックは,結構面倒です.今回は実装をシンプルにするために関数であることを型のレベルで強制しています.)
ProcV の pretty printing
“元々出ていたWarningを解消するためにpretty printingを拡張したのだが、ProcVを表すために新たにstring_of_expが必要になり、以下のような定義をしたのだが問題はないだろうか。Slackで投げるとネタバレになりかねないなと思いここで投げたが、今後pretty printingの記法が指定されることがあった時にこの辺りが原因でエラーが出ると悲しいので先に伺っておきたい。
(コードのレイアウトがちょっと面倒だったので削りました.)
多分大丈夫だと思います.が,OCamlではクロージャを出力するときに,単に<fun>と表示されます.
# let x = fun n -> n + 1;;
val x : int -> int = <fun>
#
必ずしもコードの文字列表現が手に入るわけではないためこのようになっているんだと思います.多分.
meta-circular interpreter
“少し前回内容になってしまうのですが、質問です。再帰の定義式導入のためにrecなどをsyntaxやparserに加えましたが、それらを加える前からevalにはlet rec宣言がなされていました。どうしてこのようなことが可能なのでしょうか?”
eval.ml は,現在我々が実装しているインタプリタを実現するための OCaml のプログラムです.OCaml にはすでに let rec 等のプリミティブがあるため,eval.mlはこれを用いて記述されています.したがって,我々のインタプリタが let rec を解釈できなくても,OCaml はeval.mlを解釈することができます.
それでは,我々のインタプリタの機能ををどんどん拡張して,例えば type を用いたユーザ型定義や match を用いた型推論等まで実装して,我々のインタプリタを我々のインタプリタ自身で解釈できるようになるでしょうか.答えは YES で,これができると,我々のインタプリタを OCaml で作り,我々のインタプリタに我々のインタプリタを読み込ませる,みたいなことができます.このようなことができるに至ったインタプリタを meta-circular interpreter と言ったりします.
型について
型推論
型推論という概念についてですが、「推論」という概念だけにどうしても機械学習のイメージと結びついてしまうのですが、正しいですか?
機械学習における推論は,学習されたモデルを(一般には未知の)データに適用してタスクを行うことを言うので,型推論でいうような推論とはちょっと違うかもしれませんね.個人的には型推論もプログラム中の変数の使われ方を学習しながら型を学習しているといえなくもないので,広い意味では機械学習とか人工知能とか言っても良いと思っています.
Python の型ヒント
“Pythonの型ヒントを用いて型の確認を行うmypyなどのツールでは検出が困難なエラーにはどのようなものがありますか?
例えばテンソルの形の不一致などは検出が困難ですね.これについて,最近の国際会議でこんな研究が発表されました.興味があれば読んでみてください.
Momoko Hattori, Naoki Kobayashi, Ryosuke Sato: Gradual Tensor Shape Checking. ESOP 2023: 197-224 https://link.springer.com/chapter/10.1007/978-3-031-30044-8_8
動的型付け言語に後付で型ヒントを追加する難しさ
(実行時は無視されるとはいえ)型ヒントを充実させれば、他の言語と同じ水準で静的検査ができるのではないかと思っているのですが,動的型付け言語に後付けで型の確認を取り入れるのは困難なものなのでしょうか?”
一般に後付けで型を入れるのは結構たいへんと言われています.今日ちょっと話をしたTypes and Programming Languageの第一章でも以下のように書いてあります.
Retrofitting a type system onto a language not designed with typechecking in mind can be tricky; ideally, language design should go hand-in-hand with type system design. One reason for this is that languages without type systems—even safe, dynamically checked languages—tend to offer features or encourage programming idioms that make typechecking difficult or infeasible. Indeed, in typed languages the type system itself is often taken as the foundation of the design and the organizing principle in light of which every other aspect of the design is considered. Another factor is that the concrete syntax of typed languages tends to be more complicated than that of untyped languages, since type annotations must be taken into account. It is easier to do a good job of designing a clean and comprehensible syntax when all the issues can be addressed together. The assertion that types should be an integral part of a programming language is separate from the question of where the programmer must physically write down type annotations and where they can instead be inferred by the compiler. A well-designed statically typed language will never require huge amounts of type information to be explicitly and tediously maintained by the programmer. There is some disagreement, though, about how much explicit type information is too much. The designers of languages in the ML family have worked hard to keep annotations to a bare minimum, using type inference methods to recover the necessary information. Languages in the C family, including Java, have chosen a somewhat more verbose style.
すごく雑にまとめると
- 静的型検査のない言語では,型検査を通らないようなイディオムをみんな使いがち(なので,後付けでそれらを禁止するのは互換性を保つという前提では大変.)
- 静的型検査のある言語ではどうしても annotation が必要になることがあるため,構文が複雑になる傾向がある.
といったところでしょうか.やや古い本ですが,確かに今でもそうだなあと思います.
freevar_ty
今回の課題ではありませんがfreevar_tyが何をするための関数がいまいちよくわからないです.
ty -> tyvar MySet.t 型の関数で,型を受け取るとその中に出現する型変数を集合にして返す関数です.例えば freevar_ty (TyFun(TyVar 0, TyVar 1)) は 0 と 1 からなる (MySet.t で表現された) 集合を返します.単一化における occur check で使用します.
ところで,一般にある関数が何をする関数かわからないときは,(1) その関数の型を見る,(2) その関数に対するテストを読む,ことが有用です.(なので,テストを書くことはドキュメントとしても重要.また,.mli ファイルに型を書いておくことも大事.)これは今回の演習に限らず大事なことなので覚えておきましょう.
再帰的な型
[(α,β->γ); (β,γ->α)]を同時に満たす型α,β,γが存在するか考えてみたのですが、発見できませんでした。このような型は存在し得るのでしょうか?
([(α,β->γ); (β,γ->α)] は型代入ではなく,等式制約 $\alpha = \beta \rightarrow \gamma \land \beta = \gamma \rightarrow \alpha$ という意図だと思って回答しています.)
これは今回の型システムでは存在しないです.$\beta = \gamma \rightarrow \alpha$ の $\alpha$ に $\beta \rightarrow \gamma$ を代入すると,$\beta = \gamma \rightarrow \beta \rightarrow \gamma$ となります.これを満たす $\beta$ は,型のサイズが有限であるという縛りのある今の型システムには存在しません.(もう少しフォーマルな証明ができそう.)
Pretty printing
pretty printとはなんですか?
「値を見た目良く出力する」のような意味です.我々の文脈では,抽象構文木を人間が分かりやすいように見た目良く出力することを指しています.
Soundness と Completeness
“Soundnessが重視されているとのことですが、Completenessについてはプログラミング言語の世界ではどのような扱いなのでしょうか?
授業中にも触れた決定可能性にも関わってくるのですが,型エラーが起こらないことを complete に保証する(有限の導出木のみを許す)型システムはある程度プログラミング言語の表現力が高くなると作れません.したがって,complete な型システムを作るという方向性にはあまり人々の興味が向かない傾向があるように思います.
一方で,型システムに対して complete な型推論アルゴリズムは作れる場合があります.すなわち (1) 常に停止して, (2) 与えられたプログラムに型が付くならば型推論アルゴリズムが正しい型を報告し,型がつかないならば型推論アルゴリズムがエラーを報告するようなアルゴリズムは作れる場合があります.(授業で扱う型推論アルゴリズムは,MiniML4 と,その多相型での拡張については,この意味で complete です.)したがって,型推論アルゴリズムと型システムとの関係においては,completeness は重要な性質になります.
(というわけで,何の何に対する soundness/completeness なのかって大事ですね.)
また,completeness がない場合でも,relative completeness と呼ばれる性質が成り立つことはあります.これは雑に言えば,ある決定不能な問題を正しく決定するオラクルがあればcomplete になる,という性質です.例えば命令形言語のための検証システムを与えるホーア論理と呼ばれる論理体系は,整数上の算術を含む一階述語論理式の妥当性判定が決定できるならば完全です.このような妥当性判定は決定不能であることが知られているので,実際には完全ではないのですが,相対完全性の概念を用いることで,何の問題が決定不能であることが completeness を成り立たなくしているかを正しく述べることができます.
決定不能な型システム
決定不能な型システムで実用的なものは何かありますか?
授業中で触れた篩型 (refinement types) を用いた型システムは,refinement に用いる述語の表現力がある程度高い場合に決定不能です.しかしながら,LiquidHaskellのように実用的な処理系が存在します.
実際のところ,ある問題 P が決定不能とは,「任意の P のインスタンスを正しく判定し,なおかつ任意のインスタンスについて有限時間で停止する」ような手続きが存在しないことです.したがって,(1) 「任意の P のインスタンス」という条件を諦めて,任意のインスタンスではなくある性質を満たすインスタンスしか扱えないことにする,(2) 「正しく判定」という条件を諦めて,一部のインスタンスについては正しくない結果を返すことを許容する,(3) 「有限時間で停止する」という条件を諦めて,一部のインスタンスについて停止しないことを許容する,というような諦め方をすることで,実用的な手続きを作ることは可能なわけです.
実行時型エラーが怒らないことを意味論で定義するには
実行時型エラーが起こらないことを意味論的に定義するにはどのようにすればよいのでしょうか?”
プログラミング言語の意味論において,「実行時型エラーが起こる」のはどのような場合かを形式的に定義し,そのような場合に到達可能なプログラムを「実行時型エラーが起こり得る」プログラムと定義するうことで,実行時型エラーが起こらないことを厳密に定義できます.「実行前の型検査を通ったプログラムについては,実行時型エラーが起こらない」という性質(型安全性; type safety, soundness)を証明すれば,型システムの正しさが言えるわけです.
型推論の計算量
型検査の導出規則はアルゴリズムを実装することを見据えて設計されると思うが、表現力を向上させようとした結果、型検査が多項式時間で解けなくなることがあるのではないかと思った。
上記の LiquidHaskell のように,そもそも決定可能にならないようなものもあるので,多項式時間で解けなくなるケースもザラにあります.授業で扱う型推論は,うまい実装を行えば,プログラムサイズに対してほぼ線形時間で決定することが可能です.(「ほぼ」がミソなのですが.)
Union 型
“型判断に構文木が使われているという学びを得た。typescriptのようにユニオン型を導入すればT-ifを保守的にする必要はないという認識で良いのでしょうか”
ユニオン型は有効な拡張ですが,実際にはそれでも結構問題になる場合があります.授業で扱ったような if true then 1 else false みたいな例であれば,int ∨ bool みたいな型をつけられそうですが,なにか適当な関数 f を用いて (if f 1 then 1 else false) + (if f 1 then 1 else false) みたいな例を考えると,1つ目の f 1 と2つ目の f 1 が同じ結果を返すならば型エラーになりませんが,そうでなければ型エラーが起きてしまいます.これを検証するのは(参照等を用いているせいで f が同じ引数に対して異なる結果を返しうる場合には)かなり難しいです.単純な union type では,これは困難なんじゃないかなあ.
「最も一般的な型」(主要型)の存在
質問ですが、型推論では「最も一般的な型」を推論するのが目標だと思いますが、この「最も一般的な型」が存在する証明というのはどこかで読めますか?例えば let id x = x は ‘a → ‘a がであり int → int でもあり ‘a → ‘b ではないが、’a → ‘a という最も一般的な型が存在する証明を知りたいです。”
「最も一般的な型」を主要型 (principal type) と呼びます.正確には,以下の条件が満たされるときに型 $\tau$ を princpal type と呼びます: (1) $\Gamma \vdash e : \tau$ かつ, (2) $\Gamma \vdash e : \tau’$ を満たす任意の型 $\tau’$ について,$\theta\tau = \tau’$ を満たす型代入 $\theta$ が存在する.
今回紹介している型推論アルゴリズムは principal type を推論するのですが,それには (1) この型システムで型が付くならば princpal type が存在すること,(2) 型推論アルゴリズムが princpal type を推論すること,の2つを証明する必要があります.このあたりの詳細な議論は,以前紹介した Types and programming languagesの22章にあります.(和訳がよければ型システム入門をどうぞ.)大学内からであれば電子ブックを無料でダウンロードできるので読んでみてください.
C++ における auto
(C++など)手続き型プログラミング言語では、letの型注釈のみ省略できて、関数の引数やリターンの型は省略できないことが多い ですが、どうしてか気になりました。
すみません,最近の C++ をあまり知らなくて(autoも最近まで知らなかったくらい)ちょっとこの辺りの事情はよくわかりません.いろいろ調べてみたところ,C++14では返り値の型に auto を使うことも一応できるっぽいですかね.ただ,一般に関数の引数や返り値の型は関数のドキュメントとしても役立つので,(型推論を持つ関数型言語であっても)省略せずに書くのが良い習慣だったりします.
C# におけるエスケープ解析
最近、C#の機能として参照型の参照先が存在することを保証するというのが存在するのを知ったのですが、以下のような複雑な条件式についても、出所が存在しない参照型はコンパイルエラーになるようです。
private static ref int Error(ref int x, int n)
{
ref int r1 = ref x;
int localInt = 1;
ref int r2 = ref localInt;
// r2 がローカル変数から出たものなのでコンパイルエラーになる
return ref n >= 5 ? r1 : r2;
}
この実装にも型推論と同様の仕組みが働いているように思うので、かなり便利なアルゴリズムなのだと感じました。”
おお,これは面白いですね.これはいわゆるエスケープ解析というやつで,関数内で定義された値が関数定義の外に出ていきうるかというのを解析する手法です.型を用いたエスケープ解析としてはこんな論文があります.
証明支援系を用いた soundness の証明
講義動画2本目でT-Plusの説明中にこの推論規則が実際正しいのか(導出の正当性)は別途証明する必要があるとおっしゃっていたのですが, この証明はCoq等の証明支援系の言語を用いることで証明することが可能なのでしょうか。
はい,紙と鉛筆をつかって証明することもありますし,証明支援系を使って証明することもあります.前者は参考文献に挙げた五十嵐先生の教科書や,Benjamin Pierce の教科書に詳しいです.証明支援系を使う方法はSoftware Foundationsの Volume 2 までやると出てきます.
静的型検査をいろいろな言語に
静的型解析はあらゆる言語に対して可能ですか?
何を型と捉えるか,何を型による解析と呼ぶのか,「あらゆる言語」を何と捉えるかによるかなと思います.決定可能な解析のみに話を限るとすれば,例えば停止するプログラムのみに型がつくような解析は,停止性問題の決定不能性から作ることができないです.(多分質問はそういうことではない感じもするが,まあ限界を示す一例ということで.)
既存の型を使ってない言語に型を入れる研究はあります.例えば C 言語のための篩型の話がつい最近出ました.https://pldi21.sigplan.org/details/pldi-2021-papers/11/RefinedC-Automating-the-Foundational-Verification-of-C-Code-with-Refined-Ownership-T
モデル検査を組み込んだプログラミング言語
型システムは現代の言語にとっては既に必須とも言える存在であると思いますが、モデル検査が(部分的にでも)言語の設計レベルに組み込まれた例もあるのでしょうか。
言語処理系レベルでサポートしているものはすぐには思いつきません.
関連するトピックとして,高階関数型言語のためのモデル検査を型に基づく解析で行う手法が東大の小林直樹先生によって研究されています.Naoki Kobayashi, C.-H. Luke Ong: A Type System Equivalent to the Modal Mu-Calculus Model Checking of Higher-Order Recursion Schemes. LICS 2009: 179-188 いわゆる普通のモデル検査はシステムをオートマトンでモデル化して検証することが多いように思うのですが,関数型プログラムをこのようにモデル化するのは困難なため,関数型言語での検証手法には型が用いられることが多いかなと思います.
型推論の停止性
この型推論のアルゴリズムは止まるのでしょうか。
はい,停止します.停止性の証明で非自明なのは,制約の単一化の停止性の証明です.どうやって証明すればよいかは結構面白い問題なので,考察してみてください.(クイズに出しておきます.)
型検査におけるトレードオフ
Typescriptのように「booleanもしくは数値型」というような型を明示的に宣言することで、別の型に評価されうる式を型付けしている言語を稀に見ます。個人的には一部型推論が機能しなくとも型付け可能なプログラムが増えた方が自由度が高くなって好ましいと思うのですが、なぜOcaml型付け不能にする言語が多いのでしょうか。
型検査の複雑さと利便性とのトレードオフの問題です.型システムに対する要求として,例えば (1) ユーザのアノテーションの量を少なく,(2) 自動で型検査を行い,(3) 型検査にかかる時間を短くし,(4) 実行時の型検査のオーバーヘッドをなくし,(5) 型付けできるプログラムを増やす,という要求を考えてみましょう.これらをすべて満たすのは難しいので,どれかを諦める必要があります.OCaml は
- ユーザのアノテーションはほぼ不要
- 自動で型検査が行える
- 型検査にかかる時間は短い
- 実行型検査はほぼ不要
- 型付けできるプログラムはやや少なめ
と,1,2,3,4 を得るために 5 を少し諦めることにしています.TypeScript は(僕あまり知らないので間違っているかもしれませんが)
- ユーザのアノテーションは必要
- アノテーションをつけた部分については自動で型検査を行える
- (ここはあまり知りませんが,そんなに時間はかからないイメージ)
- any 型をつけた部分については実行時型検査を行う
- 型付けできるプログラムは OCaml よりは多そう
という設計方針をとっている感じです.どう上記のトレードオフを解決するかが言語デザインの肝の一つであると言えると思います.
MiniML の型システムの保守性を排することの有用性
「型システムは保守的である」の議論についてですが、このような保守性を言語から排することで表現力が上がる例があまり思い浮かびません。これは型システムの有る言語になれてしまっているからでしょうか。もちろん全体としてあまり実害が無いので保守的なシステムが多くの言語で選択されているのだとは思いますが、この保守性を排する(より広範な表現を認める)ことが部分的にでも有用な例がありますでしょうか。
if 式の保守性とは違うのですが,リストに様々な型の値を格納したくなるというユースケースはあるかもしれません.OCaml では [1;2;3] : int list や [true;false] : bool list のように一つのリストには同じ型の値しか格納することができません.[1;true;"hoge"] はエラーになるので,こういうことをしたければ
type t = Int of int | Bool of bool | String of string
[Int 1; Bool true; String "hoge"]
のようにヴァリアント型を用いることになります.他方,Lisp や Scheme や Python では,一つのリストに様々な型の値を格納することができます.これを便利と見るか,リストから値を取り出すときに何型の値かチェックするのが不便と見るかが静的型付け脳と動的型付け脳の違いと言えるかもしれません.
上記の例が示すように,型システムが保守的なせいで型付けできないプログラムがあったとしても,ちょっとプログラムの煩雑さ我慢すれば静的型付きの言語でもそのようなプログラムに相当することを記述できることは結構あります.
fresh_tyvar
fresh_tyvarの定義に関する質問なのですが, counterはfresh_tyvarが呼び出されるたびに0に初期化されてしまうようなことは起こらないのでしょうか。
let fresh_tyvar =
let counter = ref 0 in (* 次に返すべき tyvar 型の値を参照で持っておいて, *)
let body () =
let v = !counter in
counter := v + 1; v (* 呼び出されたら参照をインクリメントして,古い counter の参照先の値を返す *)
in body
これですね.fresh_tyvar の実体は body で定義されていますが,これは
fun () ->
let v = !counter in
counter := v + 1; v
というクロージャになっています.このクロージャは自由変数 counter を持っていますが,この counter は fresh_tyvar の定義時に一回だけ束縛され,クロージャの中に格納されます.fresh_tyvar の呼び出し時には,この束縛されたクロージャが呼び出されるだけで,fresh_tyvar が再定義されたり,coutner が再定義されたりするわけではないので,fresh_tyvar の呼び出しのたびに coutner が再度初期化されることはありません.
なんで一回等式集合にもどす?
講義資料のe1+e2 式に対する型推論について「型代入 θ1,θ2 を α=τ という形の方程式の集まりとみなして,θ1∪θ2∪τ1=int,(τ2,int) を単一化し,型代入θ3を得る.θ3と int を出力として返す.」とあったが、なぜ一度型代入を等式制約に戻し、θ1∪θ2∪τ1を単一化するのかわからなかったです。また、τ1というのは型だが等式制約として扱うθ1やθ2と和集合をとっても良い理由もよくわかりませんでした。
まず
θ1∪θ2∪τ1=int,(τ2,int)
この部分は意図としては $\theta_1 \cup \theta_2 \cup {\tau_1 = \mathbf{int}, \tau_2 = \mathbf{int}}$ です.混乱させたようですみません.これは,型代入を等式制約とみなしてよいことにすれば,等式制約の集合になっていますよね?
一度等式制約に戻して型推論をし直す必要性ですが,$e_1$ と $e_2$ を同時に考えないと十分に詳細な型代入が得られない場合があるためです.
(fun x -> (* α という型変数が生成されて x : α, y : β という型環境の下で以下を型推論 *)
(x + 3) + (* こっちでは α を int に代入するような型代入ができる *)
(if x = y then 3 else 4) (* こっちではβをαに代入するような型代入ができる *)
)
というプログラムを考えると,${\alpha \mapsto \mathbf{int}}$ という型代入と ${\beta \mapsto \alpha}$ という型代入が ${+}$ の各引数から出てきます.本来はここから ${\beta \mapsto \mathbf{int}}$ ということを導いておきたいのですが,これには型代入を等式制約とみなして単一化し直すのが多分一番簡単です.
多相にできる型変数
let多相性の、「型環境内に自由に出現する型変数は多相性を持ってはならない」という点についてです。本来多相性を持ってもよい型変数が、環境に自由に出現するせいで多相性を持てないということはありうるのでしょうか。もしそれがありうるなら、このルールはT-ifの様に保守的ではないでしょうか。
型環境に自由に出現する型変数が,他のどの場所でも絶対に使われず,特定の型に具体化されないことが保証できるのであれば,その型変数には多相性を持たせても大丈夫だと思います.(多分.)現に教科書で取り上げた例
(fun y ->
let f = fun () -> y in
f () + 1)
true
は,y の型として割り当てられた型変数 $\beta$ が別の場所で true の型 $\mathbf{bool}$ に具体化されるせいで,多相性を与えてはいけないのでした.もし何らかのプログラム解析で,例えば fun y -> let f = fun () -> y in f () + 1 が絶対に関数適用されないということがわかるならば,$\beta$ がなにかの型に具体化されることもないので,多分多相性を与えても大丈夫です.(が,その場合は f を多相的に使うメリットもなさそう.)
最も保守的な型システム
授業内容には直接関係ないですが、MinMLの型判断システムが保守的であるということを聞いて、最も保守的なシステムを持つ言語とは何か気になりました。またその言語が持つ保守的な特徴についても知りたいです。
人を食ったような答えになりますが,最も保守的な型システムとは「すべてのプログラムが型付け不能」と判断する言語ということになります.この言語では,型付け可能なプログラムがないゆえに,「型付け可能なプログラムは実行時型エラーを起こさない」という性質は守られています.
まあ,こんな言語嬉しくないですよね.なので,型推論の複雑さや計算時間と,どのくらいいろんなプログラムを許すかとのトレードオフを慎重に解決することが必要になるわけです.
漸進的型付け
静的検査において、バグがある可能性を排除するために、実際にはバグが無い場合にもエラーを出す場合があるとの話でしたが、これによって動的型付けと静的型付け言語ではどの程度表現力に差が生じるのでしょうか。
「どの程度」はやや難しいなあ.もちろん実行時にしか型検査をしない言語では実行できて,静的型付き言語では(実行前に型エラーが出るために)実行できないプログラムは決定可能な型検査を行う限りは必ずあるのですが,そういうことがあって困る!ということが日常のプログラミングでどのくらいあるんだろう.
なお,静的な型付けと動的な型付けを一つの言語の中で併用できる漸進的型付け (gradual typing) と呼ばれる Siek と Taha に始まる研究があって,五十嵐先生も研究しています.興味があればこのブログを読むと良いです.
Soft typing
保守的でない型推論を実際に行なっている言語の例はありますか?実用的にどの程度複雑なプログラムまで型推論が行われるのか知りたいです。
条件分岐が起きるところで then 節と else 節の型が異なっていても良いような型システムとしては Soft Typing とかがあるかなと思います.
- Robert Cartwright, Mike Fagan: Soft Typing. PLDI 1991: 278-292
- Andrew K. Wright, Robert Cartwright: A Practical Soft Type System for Scheme. ACM Trans. Program. Lang. Syst. 19(1): 87-152 (1997)
今広く使われている言語でこういう感じの型システムをサポートしているものがあるかどうかはちょっとわかりません.見つけたらおしえてください.
型システムと抽象解釈
eval_exp と ty_exp の実装が似ているのは、eval_exp は式を読み解いていった時の最終的な値を評価し、ty_exp は式の型を読み解いていった時の最終的な型を評価するからなのでしょうか?
概ねそう考えてもよいと思います.実際には,型は値を抽象化したものになっています.例えばintは0,1,2,3,…という整数を全部intという一つの型につぶして抽象化しています.boolはtrueとfalseをboolという一つの型につぶして抽象化しています.この型という,いわば抽象化された値で評価を行っているのが型検査と見ることができなくもありません.このように抽象的な値の上での実行と,抽象化されていない元の値でのプログラムの実行との関係を研究する抽象解釈 (abstract interpretation)という分野があり,プログラム検証に応用されています.
型代入について
[(alpha, TyVar beta); (beta, TyVar alpha)]のような純粋な型に導かない型代入の場合に、どうやって「終わり」がわかりますか?一つの型代入は一回だけやるものですか?
これは前回の講義の型代入のところをもう一度復習してください.この型代入は $\alpha$ を $\beta$ に変換してから$\beta$を$\alpha$に変換するという型代入を表します.したがって,$\alpha$は$\alpha$に,$\beta$は$\alpha$に,それ以外の型変数は変化しない,という型代入になっています.
型安全でもエラーが起こる例
型安全でもエラーが起こる例にどんなものがあるのか気になった
例えば,データの serialization はそのような典型的な例です.Serialization とは,プログラムで用いられる値をディスクに永続的に保存したり他の箇所に送信したりするために予め定めたバイナリ形式に変換することで,例えば Python の pickle などが挙げられます.OCaml にも serialization があるのですが,このserializationの結果は型情報を持たないbytesという値になります.したがって,意図しない型として読み込んでしまうとエラーになることがあります.
なぜ型スキームの形は限定されているのか
for all を全体の型の外につけなくてはならない理由がよくわからなかった
$(\forall \alpha. \rightarrow \alpha) \rightarrow (\forall \alpha. \rightarrow \alpha)$ というような型を認めてしまうと型検査と型推論が両方決定不能になってしまうからです.この論文がその証明の初出で,今検索したらより簡易な証明も発表されているようです.
(fun f -> (f 1, f true)) (fun x -> x)
(fun f -> (f 1, f true)) (fun x -> x) について,「f が fun x -> x に束縛される」のが実はよくわかっていません.関数適用の引数である fun x -> x が fun f -> (f 1, f true) に適用されるが, fun x -> x は環境を変化させないので,fun f -> (f 1, f true) は空の環境で評価される,というように考えてしまいます.詳しく教えていただけませんか.
とりあえず順を追って評価がどう起こるかを説明してみます.
(fun f -> (f 1, f true)) (fun x -> x)をトップレベルで評価すると,(fun f -> (f 1, f true))を評価することによってクロージャが生成されます.- このクロージャ中には空の型環境が保持されます.
fの(fun x -> x)の評価結果への束縛で,この(空の)型環境を拡張した上で,(f 1, f true)が評価されます.- したがって,
(f 1, f true)の評価中にはfは恒等関数に束縛されており,結果として(1,true)が返ってくるというわけです.
OCaml の REPL から MiniML の各モジュールにアクセスする方法
minimlのプロジェクト内でOCamlのreplからminimlの各モジュールにアクセスする、あるいはそれができるようにreplを起動するには、どうすればよいのでしょうか
dune build時に対話式実行の時のように各関数の型を知る方法がないのがとても不便。
- まず.
utopという高機能な OCaml の REPL をopam install utopでインストールします. - プロジェクトのトップレベルのディレクトリで
dune utopを実行します.すると,MiniML のモジュールがロードされた状態でutopの REPL が実行されます. open Minimlと入力します.- これ以降,MiniMLの各モジュールにアクセスできます.
➜ isle3sw--2021-interpreter-ksuenaga git:(master) ✗ dune utop
────────┬─────────────────────────────────────────────────────────────┬─────────
│ Welcome to utop version 2.6.0 (using OCaml version 4.10.0)! │
└─────────────────────────────────────────────────────────────┘
Findlib has been successfully loaded. Additional directives:
#require "package";; to load a package
#list;; to list the available packages
#camlp4o;; to load camlp4 (standard syntax)
#camlp4r;; to load camlp4 (revised syntax)
#predicates "p,q,...";; to set these predicates
Topfind.reset();; to force that packages will be reloaded
#thread;; to enable threads
Type #utop_help for help about using utop.
─( 22:18:27 )─< command 0 >──────────────────────────────────────{ counter: 0 }─
utop # open Miniml;;
─( 22:18:27 )─< command 1 >──────────────────────────────────────{ counter: 0 }─
utop # Environment.extend;;
- : string -> 'a -> 'a Environment.t -> 'a Environment.t = <fun>
─( 22:18:31 )─< command 2 >──────────────────────────────────────{ counter: 0 }─
utop #
➜ isle3sw--2021-interpreter-ksuenaga git:(master) ✗
オブジェクト指向言語における型推論
C++やTypescriptのclassや、RustのTraitなどのOOPのオブジェクトの型検査がどのように行われているのか気になりました。subtyping有りの言語でも使えるようにHM型推論を拡張することはできますか?
オブジェクト指向の言語では、クラス継承という概念があるせいで型推論がより難しいのかなとおもったので気になりました。”
はい,可能です.Perplexityが説明をしてくれたので,これを参考にしてみるとよいかも.
また,参考文献として
- Daniel P. Friedman and Mitchell Wand: Essentials of Programming Languages, third edition. MIT Press, 2008.
を挙げておきます.EOPL という略称で知られる教科書です.Schemeという言語でインタプリタを作っていきます.KULINEにも電子版があります.9章にオブジェクト指向言語の章があります.オブジェクト指向言語の特徴としては,継承等のオブジェクト指向特有の機構に加えて,メソッド呼び出しで実際に呼び出されるメソッドが実行時にならないと決まらない点があって,ここをどう解決するかが詳しく書かれています.
fresh_tyvar
“Syntax.freshtyvarの中の一行、let counter = ref 0 in ( 次に返すべき tyvar 型の値を参照で持っておいて, _) がよくわかりません。確かにこうすれば変更可能な整数を持つことができますが、それがtyvar型になるのはなぜでしょうか。”
let fresh_tyvar =
let counter = ref 0 in (* 次に返すべき tyvar 型の値を参照で持っておいて, *)
let body () =
let v = !counter in
counter := v + 1; v (* 呼び出されたら参照をインクリメントして,古い counter の参照先の値を返す *)
in body
fresh_tyvar () を評価すると,内部関数の body が呼び出されます.body は古いカウンタの値に let v = !counter inでvという名前をつけておいて,counter := v + 1でカウンタの値をインクリメントしたうえで,vを返します.
型を見るとcounterはtyvar refなのですが,vの型はtyvarになっており,これが返されるので,全体としてはtyvarの値が返されるわけです.
制約に基づく型推論のメリット
等式制約、単一化のメリットがいまいちピンと来ていないのですが、どういったメリット、もしくは役割なのでしょう?
制約を生成して,それを解消する,という形で型推論を行うことで,MiniML3の型推論で出てきた,「今から推論して知るべき型を,型推論器への入力として渡さなければならない問題」を解決することができます.この辺の話は以前の講義で話したと思うので,講義録画も参照してもらえるとよいです.
単一化が決定不能であるようなプログラミング言語
単一化が決定不能であるようなプログラミング言語で実際に使われているものはありますか?”
単一化に限るとちょっとよくわからないですが,型推論が決定不能であるにも関わらず使われているものとしては,CoqやLiquidHaskellやHelmholtzなどがあります.
System F のメリット
“多相型がつく条件を厳しくすることで健全性を確保しているという点が面白かった。システムFが決定不能とのことですが、型が決定不能な代わりに莫大なメリットがあったりするのでしうか?型が決定不能だと型検査の段階で停止しないケースがありそうで怖いと思ってしまいます。
どの程度説得的な例かはわからないですが,こんな例を作ることはできます.
let map_pair f (x,y) = (f x, f y);;
このプログラムでのmap_pairの型は('a -> 'b) -> 'a * 'a -> 'b * 'bです.したがって
map_pair (fun x -> x) (3,true)
のような呼び出しをしようとしても,これには型がつきません. (map_pairの第2引数の型でペアの1つ目の要素と2つ目の要素が同じでなければならないという制約があるため.)
しかし,もしmap_pairの型として(∀α.α→α)→(β*γ)→(β*γ)のような型を許すことができれば,この関数呼び出しは型がつきます.なぜなら,この型では受け取った関数を多相的に適用でき,それによりmap_pairの第2引数の型についてはβ*γという型を持つペアであればよいという制約しか課せられないからです.
実は OCaml ではレコード型と明示的な多相型の宣言を用いて,以下のように擬似的にこの例を書くことができます.
type poly_f = { f : 'a 'b. 'a -> 'b };;
let map_pair p (x,y) = (p.f x, p.f y);;
ここで,poly_f の型においては,明示的に型が ∀αβ.α→β という形で書かれています.これにより,map_pair の型は poly_f -> 'a * 'b -> 'c * 'd という形になり,map_pair (fun x -> x) (3,true) のような呼び出しは型がつくようになります.
より詳細にはここを参照してください.
参考文献
型理論に関する参考文献を邦書洋書問わず教えて頂きたいです。IoPLMaterialsには参考文献が見当たらなかったので。
和書では
- 五十嵐淳,”プログラミング言語の基礎概念”,サイエンス社,2011年.
が良いかなと思います.うちの大学院では五十嵐先生と僕がこの教科書を使った講義をしています.サポートページもあります.自分で導出木を書くオンライン演習システムもあります.
また,証明支援系 Coq を使って学ぶオンライン教科書としては(英語ですが)
- Benjamin C. Pierce, et al, “Software Foundations” https://softwarefoundations.cis.upenn.edu/lf-current/index.html
があります.これの Volume 2 まで問題を解いていくと,型の話を含むプログラミング言語理論の基礎の部分が自然に見についていきます.
現在の型のスタンダードな教科書としては
- Benjamin C. Pierce, “Types and Programming Languages”, The MIT Press, 2002/1/4.
があります.λ計算という関数型言語のコアを取り出した小さい言語で意味論を形式的に定義したり,型理論を展開したり,その性質を証明する方法が解説してあります.この本をしっかり読むと,型を扱っている論文がまあまあ読めるようになります.(うちの研究室ではこれを4年生のときとM1のときと2回輪講します.)この本は京大生であればKULINEから無料で電子版が読めます.
東北大の住井英二郎さんらが和訳したバージョンもあります.
- Benjamin C. Pierce, 住井英二郎監訳,”型システム入門” オーム社 2013/3/26.
これも KULINE から読めるはずです.
型理論の応用にカリーハワード同型 (Curry-Howard isomorphism) と呼ばれる性質があります.これは型理論と論理の間の対応を与えるもので,証明支援系の理論の基礎になったりしています.すごく雑に言えば,なにか型システムが与えられたときに,その型を命題だと思って,プログラムを証明だと思うと,証明システムが得られるし,その逆も行けるというやつです.この話の教科書としては
- Morten Heine Sørensen and Pawel Urzyczyn, “Lectures on the Curry-Howard Isomorphism”, Elsevier Science, 2006.
があります.プログラミング言語の世界の型理論の話と,論理の世界の意味論や証明論やの話を丁寧に説明した良い本ですが,読むのはなかなか大変かもしれません.これも KULINE から読めます.
また,型の最近の応用に篩型 (refinement type) というのがあります.OCaml の型は int とか bool のようにざっくりと「整数値」「ブール値」のような分け方しかしませんが,これに {x : int | x > 0} という「正の整数を表す型」を導入した型システムです.x > 0 の部分に任意の述語が書けてしまうと型検査や型推論は決定不能になるのですが,これにうまく制限をかけた Haskell の拡張 Liquid Haskell というのがあります.チュートリアルが
- https://github.com/ucsd-progsys/liquidhaskell-tutorial
ここにあるようです.また,篩型のような表現力の高い型システムにおける型検査は,能力の高い制約解消ソルバが必要です.このようなソルバは,例えば x >= 0 && y < x + 1 && z < x みたいな制約は充足可能かどうかを検査したり,充足可能だとしたときに x,y,z への可能な代入を返すとかができる必要があります.このようなソルバを SMT ソルバというのですが,一番広く用いられている SMT ソルバが Z3 というやつで,これが使えるといろいろな検証器が作れたりします.OCaml のインターフェイスもあるのですが,Python からも使うことができて,Python を使ったチュートリアルが
- https://theory.stanford.edu/~nikolaj/programmingz3.html
ここにあります.やってみると面白いかもしれません.
もう少しマニアックなのがお好みであれば,F* という言語をやってみると面白いかもしれません.(地獄を見るかもしれません.)副作用を持ちうるプログラムの性質を保証するための証明支援系で,OCaml に似た文法ですが,篩型や副作用を表す型などを用いていろいろな性質が検証できます.うちの研究室ではこの言語を用いてブロックチェーン Tezos で用いられるデータ構造の実装の正しさの証明をつけたりしています.これもチュートリアルが
- https://fstar-lang.org/tutorial/tutorial.html
ここにあります.(あまりまだドキュメント化されていない言語なので,茨の道を進むつもりでどうぞ.)
動的束縛のメリット?
動的束縛の例として以下の例が授業で説明されていました.let g f = let b = 5 in f 5;; let f = fan a -> a + b in g f;; この場合,fの引数をa,bの2つにすれば良いと感じます.そのうえで,引数を1つずつ固定したいならばカリー化すれば良いように思います.つまるところ,私には動的束縛のメリットが感じられないです.ただ,コードが読みにくくなるだけのような気がします(単に静的束縛になれてしまっているからかもしれませんが).動的束縛が静的束縛よりも有用である例があれば,教えて欲しいです.
はい,個人的には同意です.ただ,環境変数やファイルから読み込んだ設定情報など,すべての関数から参照する必要があるが,それをいちいち全ての関数に引数として渡したくないようなときは,動的スコープも使い所があるかなと思います.(この例だとそういう用途はちょっと見えにくいですが.)
StackOverflow にも同じようなディスカッションがありました.僕はまだ追ってないですが,興味があれば見てみてもよいかもしれません.
また,関数の implicit parameter を型に含めることで,動的スコープを持つ変数の意図しない束縛が起こりにくいようにするような型システムがあるようです.(知らんかった.)ぱっと見で結構わかりやすい論文のようだったので読んでみるとよいかもしれません.
- Jeffrey R. Lewis, John Launchbury, Erik Meijer, and Mark B. Shields. 2000. Implicit parameters: dynamic scoping with static types. In Proceedings of the 27th ACM SIGPLAN-SIGACT symposium on Principles of programming languages (POPL ‘00). Association for Computing Machinery, New York, NY, USA, 108–118. DOI:https://doi.org/10.1145/325694.325708
Implicit parameter は実際に Scala 等の実用的な言語にも採用されているそうです.
うちの研究室メンバーから,以下のコメントがありました.
あと,静的束縛ではクロージャが定義時点での環境を保持するためによりメモリを消費します.これはメモリが貴重だったコンピュータ黎明期では大きなコストで,それを避けるために動的束縛が好まれたという歴史的な経緯があるようです.しかしメモリが潤沢にある現在では,そのようなコストを理由に動的束縛を採用することはほぼないでしょう.(要出典)
もう一つ以下のコメントも貰いました.Emacs Lisp は Emacs でライブラリを書いたり設定ファイルを書いたりするのに使われる言語ですが,動的束縛が使われています.Emacs Lisp が動的束縛を採用している利点としては https://www.gnu.org/software/emacs/emacs-paper.html#SEC17 や https://www.emacswiki.org/emacs/DynamicBindingVsLexicalBinding を見てみるとよいです.また,和賀先生がちょっとしたデモ と 二引数(?)足し算のデモ を書いています.
型環境内の束縛の順序
型環境内の束縛は自由に順序を入れ替えてよいということでしたが、その場合
let x =0; let x = true;といった宣言をした際に、型環境内の束縛の順序を入れ替えると、二行目時点の型環境で
x:intという風に判断してしまう可能性があるのではないでしょうか。
ああ,なるほど,確かにそうですね.ありがとうございます.見落としていました.型環境に含まれる変数は互いに異ならなくてはならないという制約を設けたり,変数が複数回現れてもよいが順序を勝手に入れ替えてはいけないという制約を設けたりしないといけませんね.前者の場合は,挙げてもらったプログラムが型付け可能にならないような気がするかもしれませんが,別途束縛変数は名前替えをしてもよいということにして(そうしても意味は変わらないので)例えば
let x = 0 in
let x = true in
x
を
let x1 = 0 in
let x2 = true in
x2
というプログラムに implicit に名前替えをした上で型付けをする,ということになるかなと思います.
OCaml における型エラースライシング
OCamlには 型エラースライシング (type-error slicing) のような方法でエラーが分かりやすく表示されないのはなぜなのでしょうか?
let rec f = fun x -> fun y -> let w = y + 1 in w :: yを入れてみてもyはint listじゃなくてintだよというエラーが出てきてどこでintと判断されたかまでは出てきませんでした。
型エラースライシングはシンプルな言語ではまあまあうまくいくのですが,OCaml のようにいろいろな言語機構が入っていると,どのようにスライシングすればよいかがあまり自明ではなく,かつ計算量も増大するから,なんじゃないかなと思っています.(が,試したことはないので,実際にはどうなのかはわかりません.実装してうまくいったらすごい.)
等式制約と型代入の違い
Unificationまで実装しましたが、型代入と方程式に分けている理由がよくわかりませんでした。どちらも同じ概念のように思えてしまいます。
「制約」と「解」を別の型として定義するため,というのが直接的な理由と言えそうです.等式制約は (ty * ty) list 型に,型代入は(id * ty) list 型になります.型代入は型変数から型への写像なので,id がリストの各要素の第一要素になっています.一方,等式制約は型と型との間の関係なので,各要素は ty * ty 型となっています.もし,この2つを混ぜてしまうと,型代入を (ty * ty) list として定義することになってしまいますが,これでは,例えば型代入として [(TyInt, TyInt]のように意味をなさない値を許してしまうことになります.
let多相
let多相はうまく使いこなせると便利だと思った。なぜ関数型言語でしか(?)使われないのか気になった。
便利ですよね.C++ のテンプレートや Java の Generics もある意味多相型なので,他の言語でも使われ始めているといっても良さそうです.
null safety
null安全という言葉を聞いたことがあるのですが,これは実行時にエラーが起こるため安全ということで合ってますか?それに対して静的に安全性を保証しようとしているのがOCamlの設計理念ということでしょうか?
Null safety は,僕の理解では,nullがある言語において,nullチェックをせずに変数にアクセスしているようなプログラムを検出して実行前にエラーを報告するしくみです.したがって,これは静的な検証の一種です.型システムでこれを強制することも多いと思います.実際に型に「nullになりうる値か」「nullチェックを通過した値か」を表す情報を追加して,nullになりうるのにnullチェックを通過していない可能性のある変数へのアクセスがないことを保証することができます.
構文解析について
構文解析と意味的な解析の分担
今回結合の強さや結合の方向、スコープの範囲、同じ変数名が二個以上ある時の扱いなどの話はしませんでしたが、プログラミング言語を作る際はSyntaxにこういったものはすべて含まれているのでしょうか。それともこういったのはあくまで本質的な情報ではないので後から付随的に定められるものなのでしょうか。
結合の強さや結合の方向は通常 sytnax に含めて,それにしたがって構文解析を行うように実装します.スコープや同じ変数が2個以上ある場合の扱いについては,意味論で定めることが多いです.
CやC++の構文解析
“文脈自由文法の話のときに、字句解析や構文解析の難易度が気になりました。(以前の C++ 標準では » のシンボルが、テンプレート引数のリストの終わりであることを示すために空白が必要だったという話を思い出して、難しいのかなと思いました)”
はい,昔のC++はたしかにそうでした.それ以外にもC++は字句解析や構文解析のフェーズと,その他の解析のフェーズとが分離できない場合があるという点で結構複雑です.
http://yosefk.com/c++fqa/web-vs-c++.html#misfeature-2の記事がわかりやすいです.例えば,x * y(z);という expression を考えてみます.これは
int main() {
int x, y(int), z;
x * y(z);
}
という文脈においては x と y(z) の値を掛け算する式として構文解析されるべきですが,
int main() {
struct x { x(int) {} } *z;
x * y(z);
}
においては,xが型名で,zがxへのポインタとして宣言されているため,ポインタ y を z で初期化する文として構文解析される必要があります.よって,C++では構文解析を行う際に,識別子が型名か変数名かによって構文解析の仕方を変えなければならないので,型検査と構文解析のフェーズをクリアに切り分けるのが難しいです.(現実にはどうしているのかは末永もしらん.)
nested comments
字句解析においてnested commentsは正規表現で表現できないため、個別にプログラミングして対処する必要があるとのことでしたが、プログラム上に出現するこれに類似したものに()や{}のような括弧類があるように思います。課題において、後者は構文解析で実装するのに対して前者は字句解析で実装していましたが、この違いは何に由来するものなのでしょうか。また、nested commentsを構文解析で処理することによって個別にプログラミングする必要がある問題を回避することはできないのでしょうか。
Nested comment を構文解析で対処しようとすると,構文解析のための規則がかなり煩雑になるから,というのが答えになるかなと思います.例えば,
(* (* let f x = x + 1;; *) *)
を考えましょう.Nested comment を構文解析で扱うことにするには,(* と *) とをトークンとして扱い,その間のトークンを読み飛ばす,のような規則が必要になるので,
comment:
COMMNET_START __(1)__ COMMENT_END
{ __(2)__ }
のような規則が必要になります.このときに (1) に入るのは,任意のトークンの列になるので,以下のような非終端記号でこれを記述することになると思われます.
arbitrary_token_seq:
/* empty */ { __(2)__ }
| comment arbitrary_token_seq { __(2)__ }
| __(3)__ arbitrary_token_seq { __(2)__ }
このときに,上記の(3)には任意のトークンが入ってほしいので,実際には
arbitrary_token_seq:
/* empty */ { __(2)__ }
| TOKEN_A arbitrary_token_seq { __(2)__ }
| TOKEN_B arbitrary_token_seq { __(2)__ }
| TOKEN_C arbitrary_token_seq { __(2)__ }
...
のように,定義されている全トークンについて書き換え規則を書く必要がありそうです.また,(2)で何を返せばよいかもなかなか微妙です.(何も特に返したくはないが,それに相当する値は何になる?)また,このような comment がプログラムの任意の場所に現れることを許さないといけないので,例えば
expr:
expr PLUS expr { ... }
みたいな文法は
expr:
comment expr comment PLUS comment expr comment { ... }
のように書くことになってしまいそうです.というわけで,字句解析でなんとかするほうが楽という感じがします.
Reduce 前後のアイテムの更新
reduce前後のアイテムの更新が分かりません。reduce前にアイテムを更新し、reduce後の記号を新たにシフトすると考えるのでしょうか。reduce後にスタックの状態に合致する規則を追加するのでしょうか。

これを

この文法から出てくるアイテムの closure である closure(S -> (.L)) の計算について説明してみます.
とりあえず数学的な定義を無視して,吹き出しの中に書いてあるとおりに closure を作ってみると,
- S -> (.L) は . が L の直前にあるので,L -> .S と L -> .L,S とが closure に含まれなければならない
- 1 で新たに加わった L -> .S は . が S の直前にあるので,S -> .(L) と S -> .x が closure に含まれなければならない
- 1 で新たに加わった L -> .L,S は . が L の直前にあるので,L -> .S と L -> .L,S が closure に含まれれなければならない.
- 3 で加えた L -> .S と L -> .L,S はすでに加えてあるので,closure に新たに加えるべきアイテムはない
というわけで,closure(S -> (.L)) = {S -> (.L), L -> .S, L -> .L,S, S -> .(L), S -> .x} となるわけです.
この結果の集合をよく見ると,
- {S -> (.L)} は closure(S -> (.L)) に含まれており,
- かつ closure(S -> (.L)) 中に含まれる A -> α.Cβ の形のアイテムについて,C -> γ という生成規則があれば C -> .γというアイテムも含まれている
- closure(S -> (.L)) 中のアイテムを一つでも削除すると,これらの条件を満たさない
という集合になっています.これが上記のスライドの数学的定義の意味です.
LL(k) の k
LL(k)構文解析アルゴリズムではk個先読みするということですが、衝突が起こらないような最小のkを有限時間で見つけ出すこと(もしくは、そのようなkが存在しないことを示すこと)は可能なのでしょうか?
すみません,ちょっと調べたのですがわかりませんでした.停止しなくとも良いならば
- LL(1)構文解析表を作る
- 衝突が非終端記号 X と終端記号 a である場合は,そこだけ先読みを伸ばして(例えば aa と ab を先読み記号にしてみるなど)衝突が解消するかチェックする
- 衝突がなくなるまでこれを繰り返す
とかで行けそうな気がするのですが,LL(k) であるならば k は高々いくつかということがわかってないと,この戦略では有限時間になりませんね.なにかわかったら教えて下さい.
LL(k) と LR(k) との比較
LL(k)とLR(k)を比べると、どちらの方が早く解析できますか。
同じ文法を同じ入力列で速度比較した場合ですよね.実際には実装して比較してみるしかないように思いますが,
- LR はスタックの管理があるので LL に比べて速度が遅くなりがちそう
- ただし LL はナイーブに実装するとスタックが深くなりすぎて stack overflow とか起こしそうという感覚があります.が,真面目に比較したものではないので話半分で聞いてください.
文法の曖昧性
CFGが曖昧でないことは計算不能ですが、文法の構文を定義する際に、自分の作った文法が曖昧でないということはどうやって確認できるのでしょうか。
CFG 一般では曖昧性は決定不能なのですが,講義で紹介する LL(1) や LR(0) や LR(1) では曖昧性が決定可能です.構文解析表を作ると曖昧性があるかどうかを確認できます.今後の講義で扱いますので,そちらを参照してください.
メジャーな構文解析アルゴリズム
“課題の型推論の実装が進んでいき、少しずつ理解が深まっています。字句解析の講義の中で、かなり去年オートマトンの講義で知ったことが登場しているので知識が結びついているよう感覚があります。LL(1) アルゴリズムをはじめとしたいろいろアルゴリズムが出てきましたが、実際はどのアルゴリズムがメジャーなのか気になりました。”
LL も LR もよく使われている感じがします.Wikipediaによくまとまっていたので,参考にしてみると良いとおもいます.
LL(1)
LL(1)構文解析表で表の1マスに構文規則が2つ以上入ることがないのが保証されるのはなぜですか。
自分が作った文法がLL(1)かどうかはどのようにして判断できるのでしょうか。
LL(1)構文解析表を作ったときに,表の1ますに規則が2つ以上入ることがない文法をLL(1)文法と言う,というのが正しいです.講義で言ったつもりになっていたのですが,伝わりづらかったかもしれません.すみません.
というわけで,LL(1)文法かどうかを判定するには,LL(1)構文解析表を作成して,規則が2つ以上入っているセルがないかどうかをチェックすることになります.
menhir における構文解析アルゴリズム
menhirで起こられていたconflictの意味が分かりました。menhirではどのような構文解析アルゴリズムが用いられているのでしょうか?
ここにあるように,LR(1)アルゴリズムです.
字句解析における first match
first matchを実際に使う場合はあるのか
たとえば今の演習用の字句解析器は
{
let reservedWords = [
(* Keywords *)
("else", Parser.ELSE);
("false", Parser.FALSE);
("if", Parser.IF);
("then", Parser.THEN);
("true", Parser.TRUE);
]
}
...
rule main = parse
...
| ['a'-'z'] ['a'-'z' '0'-'9' '_' '\'']*
{ let id = Lexing.lexeme lexbuf in
try
List.assoc id reservedWords
with
_ -> Parser.ID id
}
...
こう書いてあって,これは小文字アルファベットで始まる列をキーワードか識別子として認識します.これを
rule main = parse
...
| "else" { Parser.ELSE }
| "false" { Parser.FALSE }
| "if" { Parser.IF }
| "then" { Parser.THEN }
| "true" { Parser.TRUE }
| ['a'-'z'] ['a'-'z' '0'-'9' '_' '\'']*
{ let id = Lexing.lexeme lexbuf in
Parser.ID id
}
...
こう書いても同じ働きを多分します.こう書くと,例えば “else” をどう認識するかは first match で選ばれています.(Parser.ID "else" と認識されるのではなく Parser.ELSE と認識されている.)
字句解析・構文解析のためのツール
OCamlで構文解析や字句解析を行う場合はそれぞれMenhir・ocamllexというツールがありますが、OCaml以外の言語でインタプリタを作る場合はどのような代表的なツールがあるのでしょうか?
C 言語だと字句解析に flex,構文解析に bison というツールを使うことが多いのかなーと思います.他の言語についてはよく知らないのですが,Wikipedia にツールをまとめて比較した記事があったので参考になりそうです.
Nullsの計算について
Nulls等のアルゴリズムについてNullsを更新するために毎回すべての規則を見るのは計算時間がかかると思うのですが高速化することはできないのでしょうか?”
非終端記号をノードとし,$X \in \mathrm{Nulls} \implies Y \in \mathrm{Nulls}$のときに$X$から$Y$に有向辺の張られたグラフを用意して,$\mathrm{Nulls}$であることが確定しているノードから到達可能なノードの集合を適当な探索手法で求めれば,少し高速化できるかもしれません.ただ,グラフ操作のオーバーヘッドも考えると,コストに見合うのは非終端記号がまあまあ多くて,かつ不動点反復で収束するまでの回数がまあまあ多い場合かなあという気もします.(あまりちゃんと考えていません.)
先読み
先読みをどのようにするのかが気になりました
LL(1)に関しては入力がかかれたストリームの先頭の終端記号を消費することなく覗き見て,LL(1)表の情報と比較することによって行います.SLRやLR(1)の場合も入力ストリームの先頭を覗き見るのは同じなのですが,先読みをどのように使うかがやや異なります.お楽しみに.
空列になりうる非終端記号
実際に使われるような文法では εになり得る 非終端記号の割合の方が多いですか
どうでしょう.統計を取ってみないとわからないのですが,自分で文法を作るときのことを考えると,$\epsilon$になりうる非終端記号は空になりうるリストを作るときに出てきがちな気がします.それ以外のときにはあまり使わないかなあ.(個人の感想です.)
不動点反復の性質
不動点での各集合は制約を満たす最大の集合であることは証明できますか?
はい,証明できます.くわしくはこの教科書の4章や8章を読むと良いかもしれません.(実は和訳もある.お,監訳者の名前が...)あとは,Knaster-Tarskiの定理とかを読むとよいかも.
LL(k)のk
LL(k)で、実用的に使われてるkの値はどれくらいなのか気になりました”
ANTLRが一番よく使われているLL系のparser generatorだと思うのですが,LL(*)というのを使っているっぽいです.先読みのサイズが予めきまっていないアルゴリズムのようです.
左再帰除去
左再帰除去について、これを行うと元の文の論理的構造が反映されないとのことでしたが、これは各演算子の結合性や優先度などの情報も保存されないという理解で正しいでしょうか。まただとすれば、左再帰除去を行った文法を用いて構文解析木を構築してしまうと、文法的に正しいプログラムか否かの判定はできてもその後の実際の処理には役に立たないように思えるのですが、この除去後の文法に基づく構文解析木を元の文法に即した形に翻訳することはできるのでしょうか。
左再帰除去をした文法は,生成される言語としてはもとの文法と同じです.演算子の優先順序等についてですが,これは具体的に抽象構文木にどう変換するのかを見てみたほうが良いかもしれません.講義で説明した下図の右の文法で考えてみましょう.
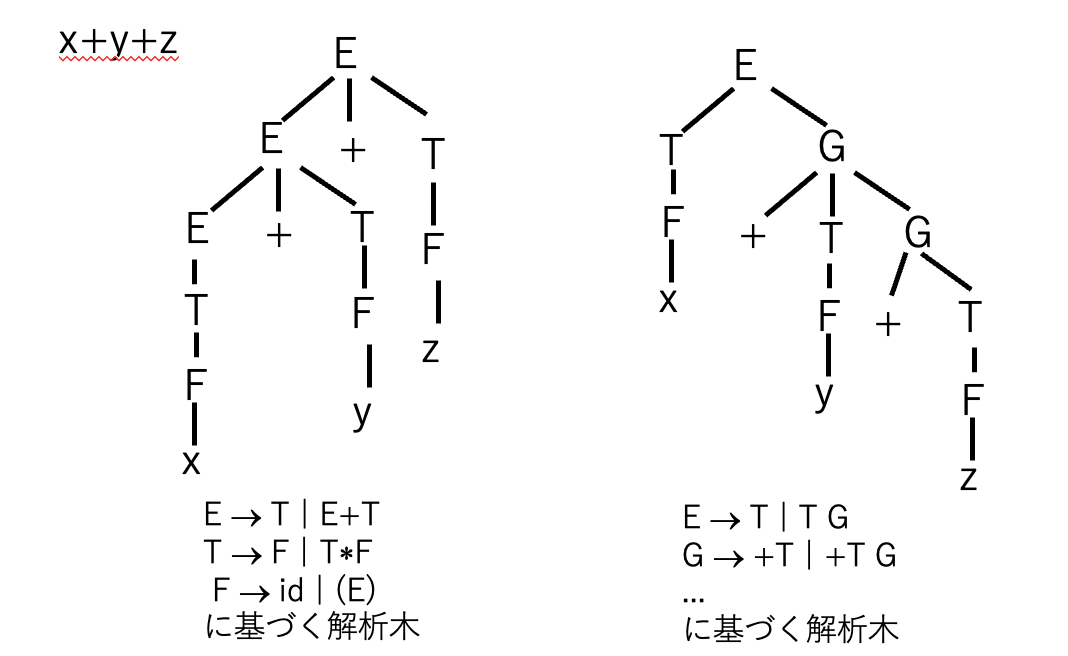
このときに,Menhir 的に書くと,以下のような形で抽象構文木が作れます.(多分)
G -> + t2=Tが使われた箇所では,fun t1 -> BinOp(Plus, t1, t2)を返すG -> + t2=T k=Gが使われた箇所ではfun t1 -> k (BinOp(Plus, t1, t2))を返すE -> t=Tが使われた箇所ではtを返すE -> t=T k=Gが使われた箇所では,k tを返す- …
直感的には,G に Syntax.t -> Syntax.t 型の関数を対応させています.Gからつくられる木は二項演算+の左の子供が欠けているような木になっています.そこで,左の子供に対応する抽象構文木を受け取って意図した抽象構文木を返すような関数をGに対応させるわけです.上記の方法に基づけば,+の結合性や優先度を壊さない形で抽象構文木が作れます.(確認してください.)
先読みを長くすると?
LL(k)やLR(k)の文法はkを十分大きくすることで、あいまいでない文脈自由文法をすべてカバーできるようなことはあり得ないのでしょうか。
LL(k)だと左再帰を含む文法は本質的に扱えないので,LL(k)についてはそのようなことはないというのが答えになるかなと思います.LR(k)文法については調べてみないとちょっとわからないです.(ただし,スライドのP245によればいかなるLR(k)文法としても書けないあいまいでない文脈自由文法が存在するっぽい?)LR(k)言語については,任意のk>0についてLR(k)言語のクラスとSLR(1)言語のクラスが一致することが以下の論文で証明されているらしいです.
- Mickunas, Lancaster, and Schneider, “Transforming LR(k) Grammars to LR(1), SLR(1) and (1,1) Bounded Right Context Grammars”, JACM, 23(3),
したがって,言語$L$を生成するLR(k)文法が存在するならば,それを生成するSLR(1)文法やLR(1)文法が存在するということになります.へー.
ところで,構文解析に関するほとんどの質問の答えは,以下の本に載っているっぽいですね.
- Alfred V. Aho, Jeffrey D. Ullman: The theory of parsing, translation, and compiling https://dl.acm.org/doi/book/10.5555/578789
FIRST や FOLLOW を計算するツール
構文解析結果を実験したいときに有用なツール等があれば教えていただけますと幸いです。(人力でやるとミスしそうです。)
僕は実は知らなくて,問題作るたびに毎回ひいひい言いながら手計算しています.誰か見つけたら教えて下さい.(一回自分で書けばよいのですが.)
と言いながら適当に調べて出てきたものを書いておきます.無保証です.
- https://www.npmjs.com/package/first-follow?activeTab=dependencies
あと,以前の TA の方からは,以下のコメントをもらいました.
自分が TA をしていた時に色々調べた中では https://mikedevice.github.io/first-follow/ が一番便利だったっぽいです。講義の記法と微妙にずれていた気もしますが、一応使えました。あとこういうのを参照してました。https://knsm.net/follow-%E3%81%AE%E8%A8%88%E7%AE%97%E3%82%92%E9%96%93%E9%81%95%E3%81%88%E3%81%AB%E3%81%8F%E3%81%8F%E3%81%99%E3%82%8B%E5%B7%A5%E5%A4%AB-d1d978ce96ec
LR(k)
LR(k)でも扱えない文法はありますか?
第12回講義の最後の方で少し喋った通りですが,$\bigcup_{k \in \mathbb{N}} \mathrm{LR}(k)$ を取ったとしても曖昧でない文脈自由文法の真部分集合になっています.すなわち,LR(k)でも扱えない文法があるわけですね.
LR(0)オートマトンにおける遷移の作り方
LR(0) の構文解析のオートマトンの受理状態に移行した後のアイテム集合を決定する操作がよくわからないのですが、以前のアイテムから受理された文字を読み出すことができるものを選んで . を進めればよいという認識であっているのでしょうか。
はい,そういうことです.もう少しきちんと書くならば,状態$q$に$X \rightarrow \alpha . X \beta$ というアイテムが入っているならば,状態$\delta(q,X)$には$X \rightarrow \alpha X . \beta$が入っているように作る,という感じですね.
衝突が起きたときの parser
“Warning: 2 states have shift/reduce conflicts. Warning: 2 shift/reduce conflicts were arbitrarily resolved.実験中、パーサに誤った変更を加えてshift-reduce conflictが起きたが、”“arbitararily”“に解消されたといい、実行はなされた。これは何が起きているのでしょうか。”
通常 shift-reduce conflict が先読み記号 a で起きた状態では,a を読むと shift がなされる実装になっていることが多いです.これを arbitrarily に解消された,と書いているものと思われます.Menhirマニュアルの6.3節を参照してみましょう.
LALR(1)
LALR(1) 文法は、LR(1) に対して先読み文字が異なるものをマージしていますが、表現力が犠牲になる割にはあまり状態数が減らないような気がします。構文解析表を作る段階で LR(1) よりも高速なところがあったりするのでしょうか。”
講義の例だとあまり減らない感じがしますが,大きい文法になると結構マージできるところがあるのだと思います.(僕もあまり詳しくない.)授業で説明した通り,LR(1)解析表を経由せずに LALR(1)解析表を作成するならば多分高速にできるのだと思います.
コンパイラについて
複数の返り値を返すには
呼び出し規約において返り値はv0とv1の2つに限られていますが、この呼び出し規約の下では3つ以上の返り値を返すことのできるような言語は作れないということなのでしょうか?pythonなどは任意個の返り値を返すことがあるように思えるのですが。
複数の値を返す方法はいくつかあって,(1) スタック経由で返す(呼び出し側のスタックの決められた領域に書き込んでから jr する)(2) 組(タプル)をヒープ上に作って,そのタプルへのアドレスを返す,あたりがメジャーかなと思います.Python の場合は後者の方法を使っているんじゃないかなと思います.
関数フレームの大きさ
ローカル領域をどれだけ確保するかはどうやって決めているのですか。
第14回の授業でやったように,各値をスタックに保存するかどうか,スタックに保存するならばどの領域に保存するかを計算して,最終的に必要となった領域のサイズ(と $ra のようなスタック上に退避場所が必要な値)を合計すると計算できます.逆にいうと,普通はコンパイル時にサイズが確定しない値はスタック上に保存しないようにすると思います.
GC
GC(ゴミ集め)では、不要なヒープ領域を開放するとありましたが、解放した後メモリの状態はだるま落としのように、不要でないヒープ領域が連なった状態になるのでしょうか。それとも、不要な領域だけを解放して虫食い状態になるのでしょうか。
これは深い質問で,やはり僕は詳しくないのですが,詳しくないなりに答えを書いてみます.これはメモリの空き領域をどのように管理するか & GC をどのように行うかの組み合わせで決まるように思います.講義で少し喋った Copy GC だと,GC は現在生きているメモリ領域だけを別の領域にコピーすることで行われるので,GC が完了したタイミングではメモリ領域は詰まった状態になっているように思います.Mark & sweep とか,手動で free を行ってかつ free された領域に再割当てが行われる可能性がある場合には,生きている領域が歯抜けのように配置される可能性があります.このような場合には,メモリのどの領域が生きているかをビットマップ等で管理しておいて,メモリ割り当ての際に空き領域中の必要な領域分を割り当てたり,空いているメモリ領域に「次の空いているメモリ領域へのポインタ」をつけておいて,割り当て時にこのポインタをたどりながら必要なサイズ分空いている領域を探す,みたいなことをするんだった気がします.
ちょっとググった感じだと http://homepage.cs.uiowa.edu/~tinelli/classes/111/Fall08/Notes/ch11.pdf この資料が結構良さげです.あと,Java については https://community.ibm.com/community/user/wasdevops/blogs/gary-deval/2022/01/18/java-garbage-collection-fundamentals これも良さげです.
あと,THe 67th Yokohama kernel reading party の動画も過去のTAさんから推薦してもらいました.
静的型検査のメリット
静的型検査について、教科書に上がっていた1億回のループを含むようなプログラムに対してだと、実行前に静的型検査を行うのはとても有意義だと思いましたが、それほど長くないプログラムの場合だと、むしろ型検査なしで実行を始めてしまって、実行していく中でエラーがあれば落ちる方式のほうが効率が上がるのではないかと思いました(つまり、静的型検査にかかる時間が長いのであれば、必要な時だけ静的型検査を実行して、他の場合は検査なしで実行した方が、短時間で実行できそう)
良い質問ですね.静的型検査にかかる時間とプログラムの実行にかかる時間とのトレードオフは確かにあります.語り始めると講義時間では足りないので,僕が静的型検査推しな理由をいくつか書いておきます.反論を歓迎します.
- 静的型検査にかかる時間は(少なくとも OCaml の場合は)かなり短い
- 実行時に型検査をする場合,そこかしこで値の型チェックが入ることになったり,値の型を実行時に持っている必要があったりする等で,実行時のオーバーヘッドが大きい(ので,静的型検査を省略するほどのお得感があまりない気がする)
- 今は実行時間がそれほど長くないとしても,開発を進めていくと得てしてプログラムが複雑になったり,実行時間が長くなったりするものである.(書き捨てのプログラムと思って書き始めたものが書き捨てで終わることはあまりない.
- プログラムの変更をバグを入れずに行うためには静的型検査があるほうが楽.
OCaml で使われている中間言語
Ocamlのコードをコンパイルする際に、実際に中間言語Cのようなものを人間がエディタで確認したり編集したりすることは可能なのでしょうか?
ocaml -dinstr と起動して何か OCaml のプログラムを書いてみてください.内部で使われているバイトコードが出力されます.他にも ocamlopt コマンドには -d... というオプションがたくさんあって,このあたりがいろいろと内部情報を出力してくれます.試してみると面白そう.
最適化による効率の変化
コンパイラがソース言語を中間言語へと変換した後, 最適化が挟まるとのことでしたが, 最適化を行うのと行わないのとではどれくらい効率が変わってくるのでしょうか…。
どういうプログラムをどういうアーキテクチャで実行するかにもよるので一概には言えませんで,実験しないと分からんなあという感じがあります.C言語ならば main.c というプログラムを
gcc -o main -O0 main.c
でコンパイルすると最適化を一切していない実行可能ファイル main が,
gcc -o main -O3 main.c
でコンパイルするとめっちゃ最適化した実行可能ファイル main ができるので,これで実験してみると良いかもしれない.
スタックかヒープか
なにかをメモリにしまうときに、それがヒープ領域とスタック領域のどちらに格納されるかをどのように決まるのでしょうか。
スタック領域は,現在の関数呼び出しが終了すると消えてしまうので,関数呼び出しの終了とともに消えてもよい情報はスタック領域に,それ以降も残っていてほしい情報はヒープ領域に格納することになります.OCaml 等ではこの区別は自動的にやってくれますが,C 言語等では自分でコントロールする必要があり,この区別に失敗したせいでバグを仕込む可能性があります.例えば C 言語では
char* f() {
char x = 0;
return (&x); // 整数を格納している領域 x へのポインタを返している
}
のような関数を書いてはいけません.関数 f 中で整数 x を格納する場所は,x が局所変数なのでスタック上に取られますが,この領域は f の呼び出しの終了とともに消えます.ところが,f が返してくるポインタは呼び出し終了後にも生き残り続けるので
char *p = f();
*p = "hogehoge";
みたいなプログラムを呼び出し元で書くことができてしまいます.2 行目での p の指す先はすでに解放されたスタック領域なので,これは解放されたメモリ領域にアクセスしている恐怖のバグです.
コンパイラはCPUごとに必要?
コンパイルの際に、CPUがサポートしているアセンブリ言語や機械語に落としていくということは、CPUの種類ごとにコンパイラは違うものが用意される必要があるということになるのですか。
はい,そういうことになります.なので,普通にコンパイラをインストールすると,今自分が使っている CPU で使うことができる機械語が生成されるコンパイラが入ることになります.
ちなみに,開発のために自分が使用している CPU と別の CPU のためのコンパイラが必要になることがあります.このようなコンパイラをクロスコンパイラと言います.
なぜ最後にアセンブリ言語を学ぶのか
この講義の最後にアセンブリ言語を学ぶ理由はなんなのか
コンパイラのターゲット言語であることと,関数呼び出しの話やスタックフレームの話を理解するために有用であるからです.僕のバックグラウンドが理論であることと,前半にインタプリタとか型推論とかをやるために,どうしても低レイヤに近い話がこの講義ではおろそかになってしまうのですが,せめてスタックの話は理解しておいて欲しいので,例年最後にやっています.
末尾再帰関数はどうコンパイルされるのか
通常の再帰ではスタックフレームが再帰の深さに比例して積まれていくと思うんですが、末尾再帰の時には使用するメモリ領域が再帰の深さによって変わらないとあるのですが、これはループ構造などとして解釈してアセンブリに変換しているのですか。それとも、普通に再帰としてアセンブリにしたらこのような性質を持つのですか?
ああ,良い質問ですね.末尾再帰のときには,jal と jr とを用いた関数呼び出しではなく,j と jr とを用いた単純ジャンプにコンパイルするように特別扱いします.例えば,講義で扱った以下の命令列
.text
.globl main
main:
addiu $sp,$sp,-20
li $a0,10
sw $ra,0($sp)
jal f
lw $ra,0($sp)
move $a0,$v0
li $v0,1
syscall
addiu $sp,$sp,20
jr $ra
f:
addiu $sp,$sp,-12
ble $a0,0,end
sw $a0,8($sp)
addiu $a0,$a0,-1
sw $ra,4($sp)
jal f
lw $ra,4($sp)
lw $a0,8($sp)
addu $v0,$v0,$a0
addiu $sp,$sp,12
jr $ra
end:
li $v0,0
addiu $sp,$sp,12
jr $ra
は非末尾再帰の関数
let rec f x =
if x = 0 then
0
else
let x' = x - 1 in
let r = f x' in
x + r
に対応しています.6行目の関数呼び出しの後にやるべき仕事(7行目)が残っているので,これは末尾再帰になっているわけです.
これを末尾再帰に書き換えた
let rec f x r =
if x = 0 then
r
else
let x' = x - 1 in
let r' = r + x in
f x' r'
は,
.text
.globl main
main:
addiu $sp,$sp,-20
li $a0,20
li $a1,0
sw $ra,0($sp)
jal f
lw $ra,0($sp)
move $a0,$v0
li $v0,1
syscall
addiu $sp,$sp,20
jr $ra
f:
addiu $sp,$sp,-12
ble $a0,0,end
addu $a1,$a1,$a0
addiu $a0,$a0,-1
addiu $sp,$sp,12
j f
end:
move $v0,$a1
addiu $sp,$sp,12
jr $ra
みたいなコードにコンパイルすることができます.もとのプログラムとの違いは,最初の f の呼び出し(8行目)は jal 命令で呼び出しているのに対して,f の中で f を再帰呼び出しするとき(20行目)では j 命令を使って f にジャンプしています.したがって,ここでは $ra は書き換わりません.末尾再帰では再帰呼び出しした f から帰ってきたときにやるべき仕事はないので,再帰が全部終了したあとの戻り先は,一番最初に jal 命令で設定された戻り先(すなわち9行目)で良いわけです.
スタックは f でも確保されるのですが(16行目)j命令の実行直前(20行目)と end ラベル中でリターンする直前(24行目)で開放されます.したがって,再帰がいくら深くなってもスタックがどんどん伸びるということはありません.
GC か手動か
ガーベジコレクションの話について、JavaやOCamlのように自動でメモリを解放してくれた方が扱いやすそうなのに、なぜCやC++では手動解放を採用しているのですか?(手動でメモリを解放する良さは何ですか?)
ガーベジコレクション (GC) に対する手動メモリ管理のメリットとしては,例えば以下のようなものがあります.
- 単一 CPU しかない計算機で GC を行う場合は,GC のたびに計算が停止する.これはインタラクティブなプログラムやロボットや組み込みシステム等では望ましくない.
- GC だと不要なメモリ領域を検出することが難しいようなプログラムがある.例えば,プログラム開始時に大きなメモリ領域を確保して,その領域を実行中にちまちま使用するような場合とか.
- 並列プログラムで効率的にかつ正しく GC するのは,GC 中に他のプロセスがメモリの状態を書き換える場合があり,かなり大変.一旦すべての計算を止めて GC をして良いのであればまだ良いが,それでは効率が辛い.
- 手動メモリ管理であれば,不要になったメモリ領域を即その瞬間に解放することが可能.また,その際の後始末のための処理もその瞬間に行うことが可能.GC ではメモリが回収されるタイミングは予言できないので,こういうことは困難.
というわけで,何事もトレードオフがあるよね.
fp
Chap5.6 アセンブリ生成で、「spレジスタとは別に,関数フレームのspとは反対側(典型的にはraの入っているあたり)を常に指し続けるfpレジスタを別に用意しておき」とあったが、反対側という意味も含めてspがどこに置かれてどういう意味を持つのかがよくわからなかった
ああ,確かにちょっとわかりにくいですね.
上位アドレス
| |
| ... |
+-------------+
| ra | |
| saved a0 | | スタックの伸びる向き
| local 4n | V
| ... |
| local 4 |
| local 0 |<- $sp
+-------------+
下位アドレス
この図で,$sp を介して saved a0 や ra にアクセスしようとすると,それらが $sp から何バイト目に置かれているかの計算が毎回入ります.これはオーバーヘッドになるので,実際は
上位アドレス
| |
| ... |
+-------------+
| ra |<- $fp
| saved fp |
| saved a0 |
| local 4n |
| ... |
| local 4 |
| local 0 |<- $sp
+-------------+
下位アドレス
のように,フレームの上位側のメモリアドレスを常に保持するフレームポインタと呼ばれるレジスタを用意しておいて,ra や saved ... はアクセスするという意味でした.$fp からだとこれらの記憶場所は局所変数のサイズによらず定数になるので,アドレス計算のオーバーヘッドがなくなります.このとき,フレーム中には fp を退避するための領域をおいておくことが多いです.
危険なCプログラム
講義内でアブナイCの挙動のお話がありましたが、このような危険な操作はどのレベルでどのように検知・阻止されるのでしょうか。
バッファオーバーラン(プログラムが書き換えるべきでないスタック上の領域を書き換えることで起こる脆弱性)については,C 言語の仕様上はこれを検知する仕組みはないと思います.実行時に検知する手法としては https://en.wikipedia.org/wiki/Buffer_overflow_protection にいろいろ書いてあるようです.(Twitter で tamaroning さんに教えてもらいました.)
コンパイラについて学ぶためのリソース
(講義資料以外に)コンパイラについて学習するにはどの文献が良いでしょうか?
コンパイラは習うより慣れろなので,教科書を読んで勉強するよりは,まずは作ることがおすすめです.作るための資料としては,授業でも紹介した東北大学の住井英二郎先生のMinCamlコンパイラがこの講義を受けた人にはおすすめです.右上のフレームの説明を順番に読んでいけば,MinCaml コンパイラの各フェーズが理解できるようになっています.
より低レイヤのことを学びたい人は植山類さんの低レイヤを知りたい人のためのCコンパイラ作成入門が良いと思います.C言語でC言語のコンパイラを書いていくという内容です.C言語のコンパイラを作るのは,C言語の挙動や低レイヤの話特有のトピックが効率よく学べるので良いです.
コンパイラの教科書のおすすめは Tiger book として知られる Andrew Appel のModern Compiler Implementation in MLです.実装言語は OCaml ではないのですが,同様の ML 系言語で書いてあるので,OCaml で実装するのもそんなに難しくないでしょう.日本語版もあります.
また,より網羅的な教科書としては Dragon book とも呼ばれる有名な教科書があります.構文解析の話がかなり詳しく書いてあり,また GC やデータフロー解析等による最適化や,コード生成における命令選択の話等も詳しく書いてあります.通読するのはしんどいかもですが,気になったところを拾い読みすると楽しいと思います.
本格的な言語のコンパイラではどのくらいの中間言語を経由するのか
本格的な言語のコンパイラでは何段階ぐらいの中間言語を経由するのか気になりました。
CompCertという Coq という証明支援系で正しさの証明をつけた C コンパイラがあるのですが,この図を見てみると8個の中間言語を経ていますね.多分コンパイラによってこの辺はだいぶ変わると思います.
{kind=link}
アセンブリ言語は読めないといけない?
上記のような問題のアセンブリ言語読解は、そらで全部できるようにしておいた方がよいのでしょうか。
進もうとする専門分野にもよりますが,現時点では不要かなと思います.もちろんだいたいのアセンブリ言語にこんな感じの命令が存在する的な知識は有用だと思いますが,あまり must ではないです.
スライドにコンパイラのターゲット言語は「通常」低級言語であると書かれていますが、高級言語から高級言語への(例えばC言語からJavaへ)変換が可能なコンパイラもあるのでしょうか。
はい,あります.例えば js_of_ocaml は OCaml を JavaScript にコンパイルするソフトウェアです.(正確には OCaml バイトコードを JavaScript にコンパイル.)
その他
プログラミング課題と大規模言語モデル
GitHub Copilotを使っているのですが([宣伝]学生は無料で使えるのでVSCodeユーザの皆さんはぜひ使ってみた方が良いと思います!)、syntax.mlやeval.mlに関数を処理するコードを追加する部分で完璧に補完だけで正しいコードが出てきてしまい思わず笑ってしまいました(parser.mlyもほぼ全部分に成功)。こんな時代にプログラマ・ソフトウェアエンジニアとして生き残っていくためにはどうしたら良いと思いますか。形式検証の専門家という立場からのお答えをお聞きしたいです。
(この辺のプログラムは頻出なので,一瞬で出てくるでしょうなあ.できれば課題は初回は自分で考えてみてね.Copilot 使うときは出てきたコードは完璧に理解してね.)
コードスニペットを Web から探して参考にすること自体はこれまでもみんなやっていたことなのですが,Copilot や LLM によってそれがかなり簡単にできるようになったという感じがします.課題を出す大学教員としては頭が痛いところですが,コード書く人間としてはいい時代だなあと思います.ただ,出力されるコードの正しさは担保されていない(というより結構間違ったコードを書いてくる)という感じがするので,テストや形式検証によって正しいプログラムを作るスキルは今まで以上に大事になるのかなあと思っています.あとは「プログラムを書ける」というスキルがコモディティ化していくことで,ソフトウェアをどう問題解決に使うのかという方向のスキルが必要になるのかもしれません.そのためには,より深く広い技術への理解やとともに,ビジネスの知識やドメイン知識を嫌がらずに学ぶことが大事になってくるんじゃないでしょうか.
ところで,GPT-4は以下のようにお考えのようです.
GitHub Copilotが役立っているようで良かったですね。AI技術の進化はプログラミングの世界にも大きな影響を与えており、プログラマーやソフトウェアエンジニアにも新たなスキルが求められています。形式検証の専門家として、プログラマーやソフトウェアエンジニアが時代の変化に適応し、生き残っていくためのアドバイスをいくつかご紹介します。
- 深い理解と知識の習得: AIがある程度のコーディングを補助できるようになりましたが、基本的なプログラミング知識や理解力は必要不可欠です。技術の基礎をしっかり学び、専門的な知識を習得しましょう。
- 問題解決能力の向上: 複雑な問題に対処し、効率的な解決策を見つけ出す能力は、AIにはなかなか真似できないスキルです。問題解決能力を磨くことで、価値あるエンジニアとなります。
- コミュニケーション能力: チームでの協力や、他の専門家との連携が重要になるため、コミュニケーション能力を鍛えることが大切です。
- 創造性と革新性: AIはあくまで人間が作ったツールです。新しいアイデアや革新的なソリューションを生み出す能力は、エンジニアにとって重要な価値を持ちます。
- 学ぶ意欲: 技術は常に進化しています。新しい知識や技術を学び続けることで、時代の変化に柔軟に対応できます。
形式検証の専門家として、これらのスキルや能力を磨くことが、プログラマーやソフトウェアエンジニアがAI時代に生き残るための鍵だと考えます。これからも努力を続け、自分自身を成長させていくことが大切です。
わしの答えとどちらが正しいであろうか.
「言語機構」の英訳
言語機構の英語訳が見つかりませんが、「language construct」でいいのでしょうか。(言語機構というのはどういう意味ですか。具体的な例はありますか。)
「プログラミング言語の機能」くらいの意味で使っていました.たしかに DeepL とかだと “language construct” が推薦されるのですが,これはどちらかというとプログラミング言語の構文要素を言っているイメージがあります. “Functionality of a language”とか “feature of a language” とかのほうがピッタリくるかも.(自信なし)
test/dune について
test/duneの仕組みが気になります。(testが失敗したときにどこが悪いのか分からなくて困っています)
dune は OCaml のビルドシステム dune の設定ファイルです. test/dune は,testディレクトリに含まれているテストが列挙されています.テストを実行したときに出るエラーに各テストの番号がついていると思うのですが,この番号は各対応している test/dune 中のファイル(例えば問題3.5.1ならex3_5_1.ml)に定義されている各テストの番号になっています.(最初が0番,次が1番…)テストが fail したときは,テストの番号からどの入力に対してどのような結果が期待されているかをテストの定義から読み解き,何が誤っているかを考えると良いと思います.
モデル検査ツール
授業とは直接関係ないですが、おすすめのモデル検査ツールあれば教えてください。”
一番お手軽に使えるのはinferですかね.従来のオートマトンベースのモデル検査器ではなく,どちらかというとプログラム論理に基づく検証器なのですが,使うのが簡単です.とりあえずこのあたりを使ってみるとよいです.
Python のための静的検証
Ocamlは静的検証を行える環境が充実しており逆にPythonなどは静的検証があまりできず実行時エラーに苦しめられることが多い、というお話でしたが、Pythonのような言語で静的検証を行うのは言語の構造上の問題で難しいものなのでしょうか、あるいは単純に言語の開発元の設計方針によるものなのでしょうか。
Python に限っていうと,静的に型がついていないのが辛いです.実行時にならないとある値が整数か文字列かすらわからない状況だと,それ以上に高度な静的検証がしにくいので.
Python の linter
Pythonのlinter(PylintやFlake8やmypyなど)がやっていることも静的検証ですか?もしそうなら静的型付けの存在意義がよくわからなくなります.
Pylint や Flake8 や mypy がどういうものかよくは知らなかったので調べてみました.Pylint や Flake8 はどちらも Python のための拡張可能な実行前チェッカーを書くためのフレームワークのようです.その意味で静的型検査とは直交するツールに見えます.(Pylint や Flake8 で静的型検査をするプラグインを書けば Python の静的型検査ツールを作ることはできそうだが,正しく能力の高いプラグインを書くのはそんなに簡単ではなさそうです.)プログラムを実行することなくコードの悪そうな点を指摘してくれるという意味では静的検証の一種だと言えます.Pylint の指摘してくれること一覧やFlake8の指摘してくれるエラーの可能性は多岐に渡っていますね.
mypy は Python のための静的型検査のためのツールで,プログラマが与える型ヒントと呼ばれるアノテーションをベースにして静的型検査を行うツールのようです.これも立派な静的検証です.ただし,一般的にもともと静的型検査のなかった言語に静的型検査を導入するのは結構たいへんなので,mypy も大変そうだなあという感じがします.
停止性検証手法
静的プログラム検証で無限ループが発生するかどうかを検査することは可能でしょうか。
一般にはこの問題は決定不能ですが,できる範囲でプログラムの停止性を検証する手法が研究されています.よく使われるのはランキング関数の生成という手法です.例えば
x = 10; y = 0;
while (y < 10) { /* (A) */
x = x - 1;
y = y + 1;
}
という C プログラムは停止しますが,ランキング関数手法に基づくこれを証明するために 10 - y という関数を発見する手法です.10 - y はループ本体では必ず正ですが(y < 10 の場合のみループに入るので)y = y + 1 という文によって 1 減少します.常に正であるのに 1 ずつ減少するということは,10 - y は無限に減少し続けることはできないので,このプログラムは必ず停止することが分かります.
実際にはここに示したような単純なランキング関数だけでなく,複数のランキング関数の組み合わせ等によって,複雑なプログラムの停止性を検証することも行われています.
インタプリタとコンパイラの違い
インタプリタとコンパイラの本質的な違いは、インタプリタは自身が構文解析をして、状態に応じて異なる結果を返すもので、コンパイラの役割は単に高水準言語をアセンブリに変換するものという認識であっていますか?
どちらかというと,インタプリタはプログラムの実行結果を出力として返すもの,コンパイラはプログラムと等価なプログラムを出力として返すもの,という理解の方が正しいです.例えば,OCamlインタプリタは
# let x = 3 in x + 2;;
- : int = 5
のように,let x = 3 in x + 2の実行結果である5を出力として返していますが,
# tmp.ml の内容を表示するコマンド
> cat tmp.ml
let x = 3 in x + 2;;
# ocamlopt は OCaml ファイルを実行可能ファイルに変換するコンパイラ
> ocamlopt -O3 -o tmp tmp.ml
# file はファイルの種類を表示するコマンド. tmp が arm64 の実行可能ファイルであることがわかる.
> file tmp
tmp: Mach-O 64-bit executable arm64
のように OCaml コンパイラは OCaml プログラムを実行可能形式の別のプログラムに変換しています.
原初のプログラミング言語について
MiniMLとは,Ocamlで書かれたOcamlのインタプリタである,という認識で正しいでしょうか.なんとなく面白いです.インタプリタなら,同じくらい高級な言語で書けるのは理解しました.一方でコンパイラは低級な言語で記述されるもので,辿っていくといつかアセンブリ言語や機械語にたどり着くのでしょうか.
MiniML は OCaml で書かれた OCaml のサブセットのインタプリタという理解で正しいです.後段ですが,多分言語 $L_n$ のコンパイラを実装するために言語 $L_{n-1}$ を使い,言語 $L_{n-1}$ のコンパイラを実装するために言語 $L_{n-2}$ を使い...と続けていくと,最初のコンパイラはどうなっているのか,という質問かなと理解しました.
実は僕はあまり詳しくないのですが,詳しくないなりに説明すると,別の言語を極力使わずに言語 L の処理系を作るための bootstrapping と呼ばれる手法があります.この手法では,L の小さいサブセット L0 の処理系を別の言語 K で定義しておき,この L0 で少し大きいサブセット L1 のための処理系を記述して L1 の処理系を得て,L1 で記述された少し大きいサブセット L2 のための処理系を記述して,L2 の処理系を得る...というようにだんだん大きい言語を定義することで L の処理系を得ます.この方法であれば,最初の L0 の処理系を作るために K を使う部分だけ別の言語を使うことになり,それ以外の部分はすべて L のサブセットで定義することができます.一般的にはこの K への依存すらなくすのは難しいんだと思います.(多分本当に原初の K まで遡ると,アセンブリやバイナリを人間が頑張って手で書いていたあたりに遡るのかなと想像します.)
バイトコードとネイティブコード
講義内で、インタプリタはプログラムの計算を実行し、コンパイラは等価な別のプログラムを返すという違いがあるという説明がありました。あるプログラムについて、インタプリタに与えて実行したときの、そのプログラムに依存する機械語と、コンパイラによって変換された機械語では、かなり違いが生じるのでしょうか。
OCaml がコンパイラによる処理とインタプリタによる処理の両方をサポートしているということは今まで知らなかったことで、驚いた。両者で何らかの挙動の違いはあるのか、また、なぜコンパイラとインタプリタの両方をサポートしているのかと疑問に思った。
OCaml のコンパイラには,OCaml プログラムをバイトコードに変換する ocamlc と,ネイティブコード(実行可能バイナリ)に変換する ocamlopt があります.ocamlcによって生成されるバイトコードは,ocamlrunというバイトコード用のインタプリタで実行することができるのですが,そうであればバイトコード生成とocamlrunを組み合わせれば OCaml プログラム用のインタプリタが作れてしまうので,このように実装されています.
ocamloptとocamlc+ocamlrunは,一応挙動の違いは内容に設計されているはずです.ただ,tupleの要素の評価順序など,意味論が未定義な部分の挙動が異なるアーキテクチャもあった気がします.例えば,
# tmp.ml の内容を表示する
> cat tmp.ml
(Printf.printf "a\n", Printf.printf "b\n", Printf.printf "c\n")
# tmp というバイトコードを生成
> ocamlc -o tmp tmp.ml
# tmp.bin という実行可能バイナリを生成
> ocamlopt -o tmp.bin tmp.ml
# 両方とも表示順序は同じ.
> ./tmp
c
b
a
> ./tmp.bin
c
b
a
上記の tmp と tmp.bin で文字列の表示順序が異なる場合が昔はありました.今はどうか分からん.
決定不能な型推論をしている言語
決定不能な型推論をしている言語の例はありますか?
C++ の型推論は決定不能なはずです.C++ にはテンプレートと呼ばれる方法で多相的な関数やクラスを定義する方法があるのですが,このテンプレートのレベルでチューリングマシンをエンコードすることができることがたしか知られています.すなわち,型推論の段階でテンプレートの解決が不可能であれば型エラーにする必要があるのですが,これはチューリングマシンの停止性問題を含んでいるので,決定不能になるんじゃないかと思います.
Unification の型推論以外での用途
Unificationの例としてはどのようなものがあるのでしょうか?型推論で扱う問題よりも一般化されたUnificationがあったりしますか?
今回扱った unification は一階の unification と呼ばれるものです.型推論以外に論理プログラミング言語と呼ばれる言語の処理系でよく使われます.例えば Prolog という言語ではプログラムを推論規則の集合として記述し,与えられたクエリが導出可能かどうかを自動的に判定することでプログラムの実行としています.これを使うと,例えば
child(fune,sazae).
child(namihei,sazae).
child(fune,katsuo).
child(namihei,katsuo).
child(fune,wakame).
child(namihei,wakame).
child(masuo,tara).
child(sazae,tara).
descendent(X,Y) :- child(X,Y).
descendent(X,Z) :- child(X,Y), descendent(Y,Z).
という,「YはXの子供である」という事実を表す child(X,Y) と,「YはXの子孫である」ということを表す述語 descendent(X,Y) の定義を与えて,
?- descendent(namihei,X).
で「波平の子孫を与えよ」というクエリを投げると
X = sazae
X = katsuo
X = wakame
X = tara
のように候補を自動的に全部出してくれる,みたいなことができます.以前の AI ブームのときには,これを中心に据えて AI を作るという動きがあったらしいです.現在では Prolog は演繹を行うデータベースで使われる datalog と呼ばれる言語の基礎になっています.また,プログラム検証ツールのための中間言語としても Prolog みたいな言語が使われています.
Unification の一般化という点では,高階関数を表す項同士を unify する高階 unification (higher-order unification) と呼ばれる問題が知られています.確か決定不能なのですが,停止しないことも許容するような手続きは存在して,$\lambda$Prolog という処理系に使われているはずです.(この辺の話,僕はあまり詳しくないです.)
型の存在理由
いまさらな質問で申し訳ないのですが、型が存在する理由とはどのようなものなのでしょうか。人間が型エラーを起こすプログラムを書かずに済むということ ( これはこれで充分すぎる理由ですが ) 以外に、計算機や計算理論の面から見た時、型の存在に何らかの利点や意味があったりするのでしょうか。既出ならすみません。
うーむ,深い問題ですね.型の応用について,いくつかランダムに挙げてみます.
- コンパイラでは値を格納するのに必要な記憶領域のサイズを型を使って決めることができます.
- 再帰を含まない型がつく関数型プログラム (この講義の MiniML3) は必ず停止することが示されています.
- MiniML3 では,型からプログラムの性質が決まることがあります.例えば,$\forall \alpha. \alpha \rightarrow \alpha$という多相型を持つプログラムは恒等関数しかありません.
- 値の使用回数に制限のある型システム(線形型; linear types)があります.この型システムはいろいろな応用がありますが,計算量との関係もよく知られています.
- プログラミング言語と論理体系の対応関係として Curry-Howard 同型対応というものがあります.これは,プログラミング言語における型が論理体系における命題と対応しており,プログラムが証明に対応する,という対応です.このような対応の下で論理体系の側から見るとむしろ型(= 命題)が先にあってプログラム(= 証明)が後に来るものととらえることもできます.
hoge とか fuga とか foo とか bar とか
プログラミングで(授業のmiroのように) hoge やfuga という言葉がよく出てくるが、なぜこのような名前なのでしょうか?
なぜかはわからないが,とりあえず仮の変数名とか名前をつけるときに,日本の(主に中年以上?)プログラマは hoge とか fuga とかを使います.こんなまとめがあった.
海外では foo とか bar とか baz とか使います.これもこの Wikipedia の記事に詳しい.
OCaml ってどのくらい使われてるの?
OCamlを今後使うことになることはあるのでしょうかと感じています…
絶対あるよ!
OCaml は結構産業界でも使われていて,OCaml のサイトではOCaml を使っている企業のリストがあったりします.Tezos というブロックチェーンで使われたりしていて,使えると意外といい言語ですよ.(我田引水)